Sourcegraph universal code search enables you to explore, navigate, and better understand all your code, faster.
Recently, we've been working to scale Sourcegraph cloud's index to 1 million open source repositories and beyond. Part of that effort has been reducing the RAM usage for the Zoekt (pronounced "zooked") servers responsible for handling most of our code searches.
Zoekt is a Go program created by Han-Wen Nienhuys that performs trigram-based regex search, which means that it builds an inverted index mapping every three-letter sequence of characters, or trigram, to where it appears in a repository. Each entry in the list is called a posting, and the list itself is called a postings list. When searching for a string like Errorf, Zoekt will iterate through the postings lists for Err and orf to find offsets where an Err trigram is found three characters before an orf trigram. The locations and lengths of these postings lists on disk are kept in RAM, along with various other metadata, to make searches go faster. Determining that a repo has no instances of a trigram that is required by the input lets the entire repository be skipped.
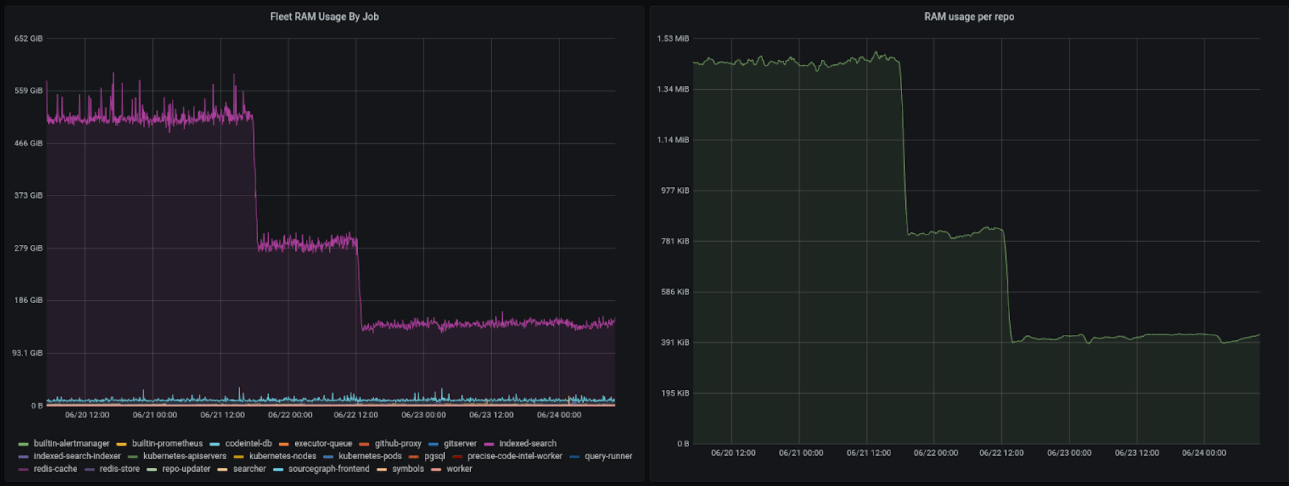
In the below image, the large purple area on the left is the RAM used by the 20 Zoekt replicas alone, and the tiny lines under it are all the other jobs. The drops represent deploying the changes described in this post.
Here's how we achieved a 5x reduction in memory usage with no measurable latency changes.
Step 1: Measure how a server's RAM is being used
As a first optimization step, a test corpus was created from one of the Zoekt backend servers, and a memory profile was collected to measure precisely how a server's RAM was being consumed. The corpus has 19,000 different repos, 2.6 billion lines of code, and takes 166GB on disk. Go has built-in profiling tools with deep runtime integrations that make it easy to collect this information. The memory profile below shows 22GB of live objects on one server. The actual RAM usage of a Go program depends on how aggressive the garbage collector is. By default, it can use roughly twice as much memory as the size of the live objects, but you can set the GOGC environment variable to more aggressively reduce the maximum overhead. We run Zoekt with GOGC=50 to reduce the likelihood that it will exceed its available memory.
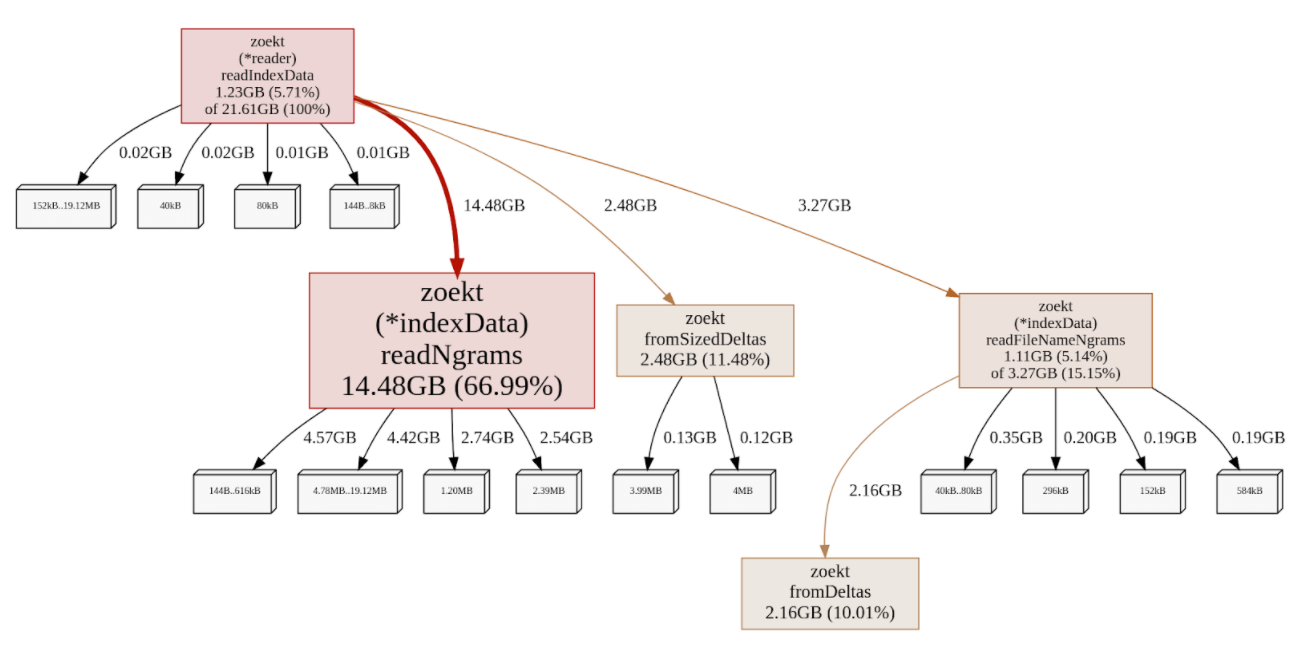 *22GB of live objects on one server.*
*22GB of live objects on one server.*
The memory profile shows which functions are responsible for allocating RAM, and it's immediately apparent that readNgrams is responsible for 67% of the memory usage. Digging into the code, this turned out to be a function that builds a map from trigrams to the location of a posting list on disk. It's building a big mapping from 64-bit trigrams (three 21-bit Unicode characters) to 32-bit offsets and lengths.
type ngram uint64
type simpleSection struct {
off uint32
sz uint32
}
const ngramEncoding = 8
func (d *indexData) readNgrams(toc *indexTOC) (map[ngram]simpleSection, error) {
textContent, err := d.readSectionBlob(toc.ngramText)
if err != nil {
return nil, err
}
postingsIndex := toc.postings.relativeIndex()
ngrams := map[ngram]simpleSection{}
for i := 0; i < len(textContent); i += ngramEncoding {
j := i / ngramEncoding
ng := ngram(binary.BigEndian.Uint64(textContent[i : i+ngramEncoding]))
ngrams[ng] = simpleSection{
toc.postings.data.off + postingsIndex[j],
postingsIndex[j+1] - postingsIndex[j],
}
}
return ngrams, nil
}
Step 2: Implement a more compact data structure for locating postings lists
Go maps provide O(1) access times, but they consume a fair amount of memory per entry— roughly 40 bytes each. Since this mapping is taking two-thirds of our memory, it's worthwhile to implement a more compact data structure for it. There are many different kinds of dynamic mapping data structures, but when all you need is a dense static mapping, it's hard to beat sorted arrays and binary search. Binary search has logarithmic lookup speeds, but accessing this map is not a bottleneck, so using much less space in exchange for slightly slower lookups is a good tradeoff.
Note that simpleSection.sz is computed by subtracting subsequent values of postingsIndex. On disk, the posting lists are written in order of ngram values, but this first implementation uses a map so it's not possible to subtract the neighboring values. Storing these mappings as two slices instead of a map reduces its memory usage from 15GB to 5GB.
type arrayNgramOffset struct {
ngrams []ngram
offsets []uint32
}
Step 3: Cut 64-bit ngrams in two
For slightly more complexity, the 64-bit ngrams can be cut into 32-bit top and bottom pieces. Thanks to how the rune packing works, this is very similar to the top half representing the first character of the trigram, and the bottom half being the second two characters. This reduces memory usage even further to 3.5GB.
type arrayNgramOffset struct {
tops []topOffset
bots []uint32
offsets []uint32
}
A three-level trie over the runes of a trigram uses 20% more memory than this simple two-level split, mostly due to the additional overhead from the third level of offsets.
Step 4: Split ASCII and Unicode trigrams
These trigrams take 64 bits to represent three 21-bit Unicode characters, but most source code and trigrams that we index are 7-bit ASCII. This can be used with a more complex scheme to have two mappings, splitting ASCII trigrams from Unicode ones, reducing the memory used for these offsets from 3.5GB to 2.3GB.
Step 5: Other metadata optimizations
Shrinking the ngram offsets to a fraction of their size means that the heap profiles start to be dominated by other functions that were previously negligible. Some pieces of metadata were changed to be kept on disk or in a compressed form until accessed. Filenames have a trigram index just like file contents, but their postings lists are loaded into memory and decompressed. Leaving them compressed until needed reduced their memory from 3.3GB to 1.1GB.
Zoekt stores offsets in its posting lists according to the number of Unicode runes, not the number of bytes, and they must be converted during searches. To make this faster, the byte offsets for every 100 runes are stored. This scales linearly with the total size of a repository. Since most source code content is ASCII, a simple compression scheme reduces this from 2.3GB to 0.2GB by turning offsets like {0, 105, 205, 305, 430} into only the points where the one byte per rune assumption didn't hold: {{100, 105}, {400, 430}}
As a nice trivial optimization, if you copy a slice that grew dynamically into a precisely sized one, you don't waste the unused trailing capacity, which saves another 500MB across our test corpus. Slices grow exponentially when needed in order to make appending to them take constant amortized time, but after it's done being appended to this excess capacity is no longer necessary.
func shrinkUint32Slice(a []uint32) []uint32 {
if cap(a)-len(a) < 32 {
return a
}
out := make([]uint32, len(a))
copy(out, a)
return out
}
Results and what's next
 *4GB of live objects after, with all optimizations applied.*
*4GB of live objects after, with all optimizations applied.*
Putting it all together, the new memory profile looks like this: a 5x reduction overall, which means we can serve search queries for five times more repositories without requiring any more servers. We went from 1400KB of RAM per repo to 310KB with no measurable latency changes.
In the future, even more of what's currently loaded into RAM can be placed back onto the disk, using memory mappings to let the OS cache pages as necessary. Larger-scale architectural changes, like having an index cover multiple repositories, or having one large inverted index for each server, will reduce RAM usage even further. These complex changes require more careful planning, coding, and testing than the simple, targeted optimizations described above, but are the best way to escape from the local minima that repeated micro-optimizations can reach.
Look out for Han-Wen Nienhuys, creator of Zoekt, in an upcoming episode of the Sourcegraph podcast!