Toward infinite context for code
Sourcegraph and Google team up to evaluate long-context models for code generation. Discover how Cody can leverage Gemini for better code assistance.

Sourcegraph and Google team up to evaluate long-context models for code generation. Discover how Cody can leverage Gemini for better code assistance.
Today's frontier models excel at using popular OSS libraries to build simple apps from scratch. But generating code for private codebases hits challenges around hallucinated APIs, subtly incorrect code, and wrong or misleading answers to technical questions.
Sourcegraph has pioneered the application of generative AI to enterprise codebases with Cody, the first AI coding assistant to incorporate code search and code intelligence into AI code generation. This focus has allowed us to deploy Cody to some of the leading enterprises, such as Palo Alto Networks and Leidos, which have massive codebases that power billions of dollars of revenue and digital infrastructure. One of the next frontiers we're examining is long context window models, which present an interesting set of questions for the next evolution of code AI. For instance, will long context models replace RAG in real-world coding settings? Let's take a deep dive and find out.
Note: this post is about our experiments with long-context window models and covers some features that aren't yet available in Cody today.
Sourcegraph is partnering with Google to evaluate how long-context window models perform in real-world coding scenarios. In this post, we focus on technical question answering as a key inner-loop development task. We find incorporating long context models into Cody improves 3 key quality metrics while reducing the rate of hallucination:

This chart compares Cody using Gemini 1.5 Flash with a 1M token context window to Cody's production version as of September 20, 2024 against our internal technical Q&A evaluation suite. The evaluation suite includes a selection of questions that range from specific searches to high-level questions. Here are some example questions:
The three metrics reported are defined in detail below, but here's a summary of what they measure:
In addition, we found the use of long-context models to significantly reduce the overall hallucination rate:

Here, we dive into the definitions of the benchmarks we used above in our evaluations. We have chosen these metrics to address shortfalls for traditional information retrieval metrics, which were constructed for a more traditional "ten blue links" search UI. The first two of these metrics are Essential Recall and Concision.
For each question in our evaluation set, we identify a list of "essential" facts that must be included in the answer for it to be considered complete or comprehensive. For a simple question like, "Where is the login page defined?", the list of essential facts would be the file or list of files that define the login page in the current codebase. A question like, "What LLMs does Cody support for chat" would have a list of all the supported models in Cody (by our count, 11). We define essential recall to be the percentage of essential facts present in the response.
Another factor in response quality is verbosity. An LLM trained to be more verbose will have a higher chance of generating an output that mentions an essential fact. But more concise outputs are preferred, provided the output covers the essential facts. We define "essential concision" as a metric that normalizes essential recall by response rate. Essential concision is defined to be 100 * E / C, where E is the number of essential facts emitted in the response and C is the character-length of the response. The constant of 100 exists because 100 characters seems sufficient for a knowledgeable and concise human to convey a discrete fact. Thus, a score of 1 on this benchmark comes close to what we'd expect from a senior member of the engineering team.
While recalling the essential facts is important, many answers may include additional pieces of information that are non-essential but nonetheless helpful. Such responses should be rewarded for providing helpful information, even if this information is not strictly essential.
At the same time, non-essential answers are not always helpful. Some statements are factually true, but irrelevant; and others are completely inaccurate. To capture these nuances, we define two additional metrics: hallucination rate and helpfulness.
We define the hallucination rate to be R_halluc = H / (H + L), where H is the number of helpful truths and L is the number of lies. 1 - R_halluc is roughly analogous to "precision" in classical search metrics.
We define helpfulness as H_help = 100 * (1 - R_halluc) * H / C. In other words, we take number of helpful facts, normalize by the non-hallucination rate, and divide by the total character count over 100 (again assuming a roughly 100 character budget for conveying each fact). In addition to penalizing actual incorrectness, this metric also penalizes irrelevant statements, because these contribute to the length of the response.
No analysis is complete without showing off specific examples, so let's examine some:
Here's Cody's answer with a 10k context window for results fetched from sourcegraph/cody:

And here's Cody's answer with a 1M context window:

*Note: Gemini 1.5 was experimental at time image was generated and as of training cutoff date of the model*
The 1M context window provides a more comprehensive, authoritative answer. There is also less noise and irrelevant filler, as the model doesn't feel the need to attend to irrelevant facts in the absence of clearly relevant ones.
Here's Cody's answer with a 10k context window:

Here's the answer with a 1M context window:

In this example, the answers are roughly comparable, but the answer from Gemini is more to the point. In general, Gemini seems very good about answering the user query directly, without elaborating on other context items that don't relate directly to the user question.
Here's Cody's answer with a 10k context window:

And with a 1M context window:

In this example, the short-context window model is unsure of itself, because it has been prompted not to treat the provided context as authoritative.
Most examples in our dataset improved with the addition of long context. However, we did notice a class of examples where long context alone was insufficient. These examples came from larger codebases, where the size of the codebase greatly exceeded the context window size. Let's take a look at some of those.
Here, we take a look at a much larger repository, sourcegraph/sourcegraph-public-snapshot. Here's Cody's answer with a regular-context LLM:

Here's Cody's response with Gemini Flash Long Context and no global retrieval:

Here, the long context window model uses a large amount of context gathered from files in the neighborhood of the currently open file. Without the benefit of global retrieval, however, it misses relevant facts in a very distant part of the monorepo.
Here's another example of a question asked over the scope of a large monorepo, sourcegraph/sourcegraph-public-snapshot. This is the Cody response with a regular-context LLM:

This is the Cody response with Gemini Flash Long Context and no global retrieval (two examples are shown where we've precached different subtrees of the monorepo):

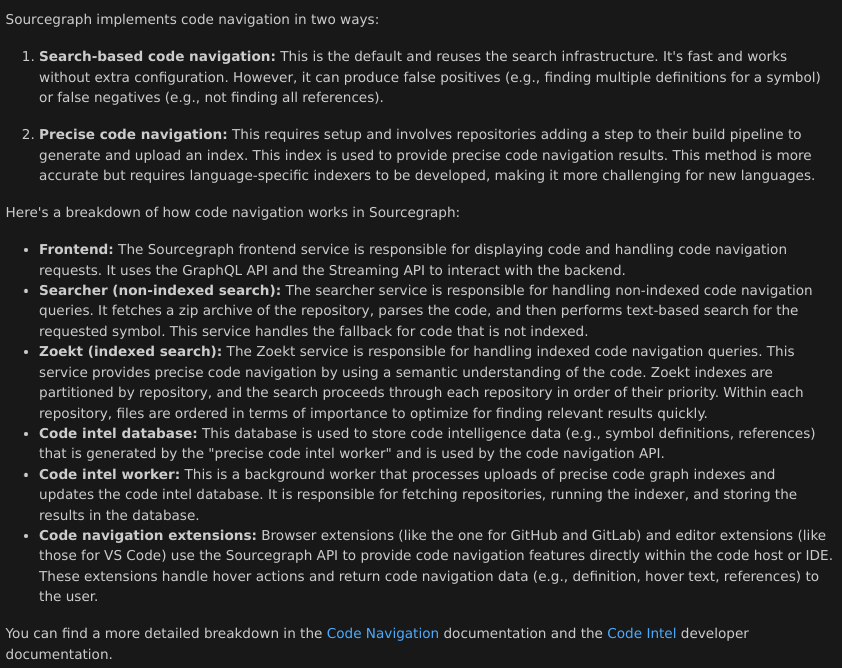
Here again, we're pulling facts from very disparate parts of the codebase, so the long-context caching approach we implemented (covered below) can only get part of the answer at a time.
Our evaluations suggest long-context window models can match the use of local retrieval methods for codebases under 4MB entirely. But for larger codebases, the addition of global code search and code intelligence remains necessary for many common queries and use cases.
One drawback to using long-context window models is that the time to first token increases linearly with the length of the context included. A solution is to prefetch as much of the context ahead of time, run model inference up to the prefetched context, and cache the model execution state.
With the Google Gemini Flash and Pro long-context models, we observe the time to first token fall from 30-40 seconds on a context length of around 1MB to around 5 seconds, which is far more acceptable for code generation and live technical question use cases.
Of course, this does require that the prefetched context is stable enough so that it can be used from request to request. We have developed a novel layered context architecture, to preserve as much of the cache as possible across requests while still enabling a substantial portion of the context window to be tailored to each specific request. These layers are:
The permalayer encompasses a sort of the "logical codebase" that surrounds the code being examined or edited. In small codebases, this can include an entire repository. In our experiments, we allocate around 90% of the total allotted context to this layer.
The action history covers an append-only record of user actions, including files opened, code navigation actions, edits, and actions taken outside the editor in other tools. The append-only nature means that we can periodically cache the combination of the permalayer and past actions, so that all of a user's actions before N minutes ago are present in the cache.
The final layer comprises long-range retrievers such as code search and code navigation actions that fall far afield from the current active file. This layer comprises a small but important element of the context, as crucial function definitions, relevant packages, and usage examples may be defined in distant locations in the file tree or outside of the current codebase altogether. Just as these mechanisms prove more critical to humans as the size of the codebase grows, so too do they become more critical for AI software creation.
We are excited about future improvements to long-context LLMs. In collaboration with Google, our experiments show that long context window models enhance many of the core use cases that have emerged in AI-assisted software development. Code search and graph retrieval remains essential for large enterprise codebases, but longer context windows are a multiplier on the quality of the RAG engine, as more results can be considered. And for smaller codebases, stuffing the entire codebase into context may soon become a popular alternative to local context retrieval.
There are still tradeoffs around latency and cost, but we expect these to improve over time and look forward to being able to soon roll out ultra long context window models to a subset of our users and customers.
As the landscape continues to evolve, Sourcegraph is excited to partner with Google in the evolution and usage of long context models for real-world use cases in large-scale codebases. Big code is the code that makes the world go round and it represents the true "dragon of complexity" that modern software engineering will need to confront in the era of AI.

With Sourcegraph, the code understanding platform for enterprise.
Schedule a demo