Strange Loop 2019 - Improving law interpretability using NLP
Overview
The process of legal reasoning is heavily reliant on information stored in text, but while legal texts are generally easily accessible, their interpretation often isn't straight forward, making the understanding of the law effectively inaccessible to the general public.
Problem
What are we working with?
- Law: a rule made by a government that states how people may and may not behave in society
- Problem: Law is not fun to read, and not “dead easy” to understand
What did we do?
Objective: Make laws more understandable and accessible
Challenges:
- Language in law is organized in a different way than other texts, a lot of references => breaks traditional parsing algorithm
- Terms are context-specific, the true meaning depends on the words around it
- Syntactic complexity is non-linear, it is very hard to understand a cluster of words sometimes
Methodology:
- Pre-trained NLP models
- Unsupervised ML
- Extract information:
- Rules
- What entities are responsible for compliance
- Organize rules into homogeneous groups based on the entity responsible
Technology:
- SpaCy library
A little grammar review:
- Subject: The word or phrase that indicates “who” or “what”
- Object: The entity that is acted upon by the subject
- Stop word: a word that's used so much that instead of adding information, they add noise.
Use case: Accessibility for Ontarians with Disabilities Act (AODA)
Burden: a requirement or obligation that organizations have to comply with. E.g. Physical and architectural barriers, documentation and training
Three Major Steps
-
Burdens Extraction: identify sentences in the law and express a rule. Found limited vocabulary: shall must, oblige, require. Then use wordnet to find groups of synonyms connected by semantic meaning.
- For each sentence, extract lemma from each token, if any of the lemmas is included in the ontology, label as burden
- Result: accuracy is 89% (required the speaker to actually read the law => not fun!)
-
Subjects identification
- Objective is to identify the subject of the sentence for each burden
- Example: "Obligated organizations that are school boards or educational or training institutions shall keep record of the training provided".
- Solution: identify the subject of the sentence using the dependency parsing tags
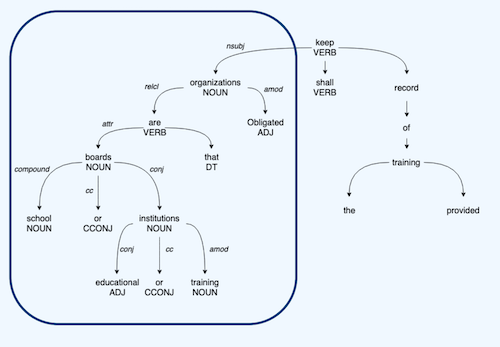
- Subjects clustering
- Objective is to organize burden into homogeneous groups based on the entities that they affect
- Look for kind of patterns or regularity? Eg. Public vs private responsibilities, or similarities across industries
- Solution: sentence normalization (lemmatization, stopwords); vector representation; dimensionaltiy reduction; clustering
Conclusions
- The difference between public and private sector is not clear
- Focus on physical barriers and transportation
- Large proportion dedicated to administration and standard definitions
- Ambiguities with respect to responsibilities in the last group
Summary of talk
- General approach to the analysis of legislation that doesn’t require a labelled training set
- Automate the extraction of rules
- Identify entities that are responsible for compliance
- Organize rules into homogeneous groups with respect to their impact on various entities
- For lawmakers: this is useful for them to identify ambiguities in the legislation