Strange Loop 2019 - Computer Vision and NLP for Multi-Task Fashion Modeling
Overview
Shoprunner aggregates millions of products from 140 retailers which represent thousands of brands. In order to make these products findable and searchable by users it is important for Shoprunner to be able to standardize the attributes (style, color, pattern etc) of these millions of products. Even after defining what attributes to model, choosing the best way to predict attributes is difficult because every product can be represented in a variety of forms such as images, product description, title,and brand name. These different data representations each have their strengths and weaknesses. Images encode information such as color and pattern well while other attributes related to length and cut may be well captured in text descriptions. This session will go through the multi-task learning ensemble that the Data Science team at Shoprunner has built using both custom multi-task CNNs for images and fine-tuned Bert model for text classification in Pytorch for attribute modeling.
Problem:
Working with 140 vendors means Shoprunner receives a lot of data from partners of various levels of technology and data sophistication. As a result, the data is messy. For example, some vendors may describe the color of their garments using common color words like "red," "white," or "green," while others may use words like "ruby," "cream," or "emerald," particularly if they want to convery a sense of haute fashion (see Apple's controversial "midnight green" iPhone 11.) However, more normalized feature extraction for colors, styles, and other metadata is important for website features like visual similarity, recommendations, and search.
Product listings also take a variety of forms. Many products have multiple images. Some are just of the product on a white background, some involve human models, while others may be highly zoomed into the fabric without any context that shows what kind of garment it is. Further, text data from the vendor may be extremely messy, even including text encoding errors and text artifacts or copypasta.
Solutions
Shoprunner's machine learning team relies heavily on a technique for deep-learning neural networks called multi-task learning. Multi-task learning works very well in environments where distinct features, while genuinely distinct, all fall in a similar domain - such as color, style, and pattern of a garment. In multi-task learning, neural networks are trained to predict a class from a single attribute set (e.g. style), but rather than simply learning from labeled styles, the model also learns and derives weights for other attributes as well (e.g. color, pattern.) It seems possibly intuitive that a model that predicts style could be improved by training on color and pattern, but more counter-intuitively, a correctly designed multi-task learning model can also more accurately predict color based on style and pattern as well!
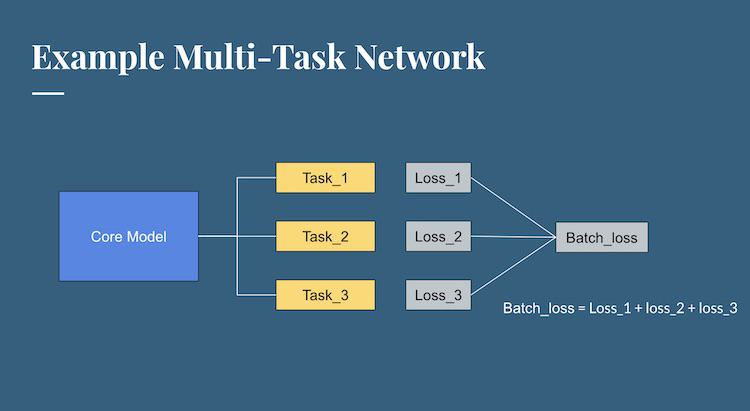
A typical model architecture follows: In this model, the three task layers perform the classification. Each his its own calculated loss, which are converged into a unified batch loss (using simple addition - for reasons that seem unclear to me, but the speaker insists are well-understoof but outside the scope of the talk.) This batch loss is the loss for backpropogation to the core model, similar to the methodology of a more traditional convolutional neural network.
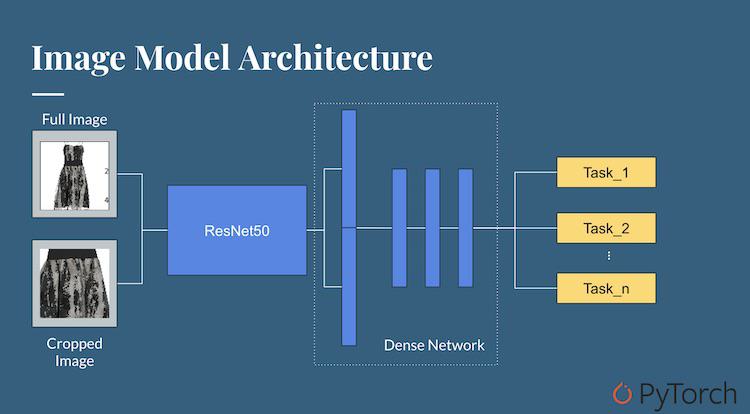
In Shoprunner's specific CNN for images, the core model is ResNet50, which requires 224x224px images. The size of the neural network scales as the square of the image dimension, so larger images create massive performance hits. Commonly, images used to train REsNet and similar architectures require downsampling of the image. For many applications, even given the lossy nature of this technique, high quality image recognition can be attained. However, the Shoprunner team discovered that the detail in fashion pieces required for things like style and pattern prohibited this common data normalization technique.
Interestingly enough, the solution here lies in a classic photography technique. Michael has some formal photography training, and one important concept is "the rule of 30s," which suggests that obtaining the best framing for a photograph involves mentally drawing a tic-tac-toe grid of 3x3 over the subject and keeping the most important part of the photo in the center. Since many photographers follow this rule either implicitly or explicitly, finding the center 224x224 will often find the most interesting part of the photograph. This allows the model to be trained on an appropriate size of image for ResNet that maintains the resolution necessary to imply more subtle elements.

So the core model is trained on both a downsampled version of the original image, and a center-cropped version, which works well for many, but not all, product photos. Some vendors send images that are more artistic in style, that maybe bend the rules of composition to create a specific effect. For these photos, the team is developing a new algorithm for clothing detection that draws bounding boxes around areas of the image that appear to be articles of clothing.
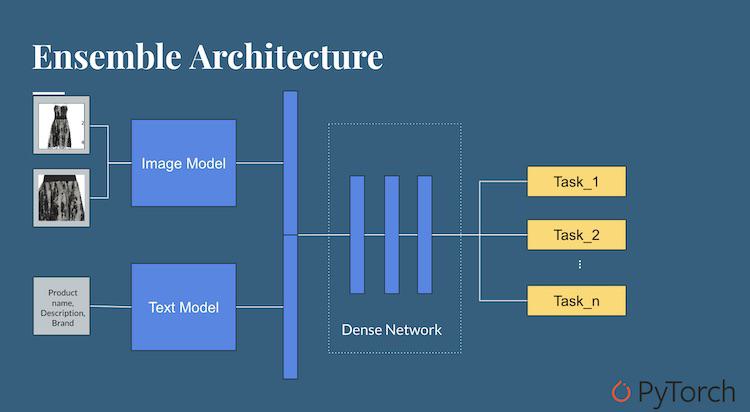
Finally, vendors send description data in free text form. Shoprunner uses Google's BERT library for natural language processing (NLP.) In late 2018, Google released a version of BERT using multi-task modeling. This model, while still early, enables a broad range of NLP that Michael describes as "the ImageNet moment for NLP," by which I assume he means BERT's multi-task model may aim to be the one NLP model to rule them all.
Putting the image model and the NLP models together in multi-task form, Shoprunner has a highly effective multiple attribute classifier with a relatively small number of distinct learning models.
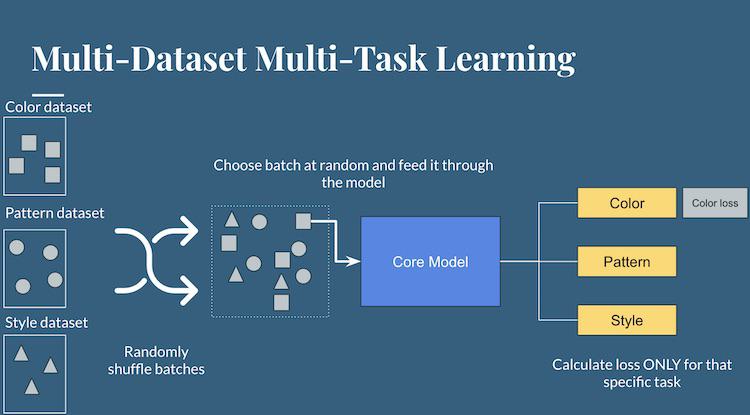
This generalized model performs well, but there are more features to identify and add. The team has developed a novel way to add new attributes to the model called multi-data multi-task learning, which involves shuffling labeled datasets that are partitioned by feature label. Loss for each individual task is calculated until all datasets have been used for training.
Ongoing and future work involves adding more relevant attributes, and integrating the model with more services at the company - from search, to relevance, to style personalization, and outfit matching.