gRPC in production
Today, he's giving us a whirlwind tour of gRPC and how to use it in your production web service.

Today, he's giving us a whirlwind tour of gRPC and how to use it in your production web service.
Liveblog by Beyang Liu (@beyang)
Alan Shreve is an hacker, entrepreneur and creator of ngrok.com. ngrok is the best way to connect expose services behind a NAT or firewall to the internet for demos, webhook development and IoT connectivity. Today, he's giving us a whirlwind tour of gRPC and how to use it in your production web service.
Q: How do Microservices talk to each other?
A: SOAP. Just kidding. Today, it's mostly HTTP + JSON.
I will die happy if I never write another REST client library in my life.
It's a lot of repetitive boilerplate.
gRPC is a "high-performance open source universal RPC framework."
Let's build a caching service together using gRPC.
We don't define it in code. We actually define it in an Interface Definition Language (IDL), in this case, protobufs.
Here's our caching service (app.proto):
syntax = "proto3";
package rpc;
service Cache {
rpc Store(StoreReq) returns (StoreResp) {}
rpc Get(GetReq) returns (GetResp) {}
}
message StoreReq {
string key = 1;
bytes val = 2;
}
message StoreResp {
}
message GetReq {
string key = 1;
}
message GetResp {
bytes val = 1;
}
Snap your fingers and now you have client libraries in 9 different languages: C++, Java (including Android), Python, Go, Ruby, C#, JavaScript, Objective-C, PHP.
But wait, there's more: you also have server stubs for that API in 7 languages: C++, Java, Python, Go, Ruby, C#, JavaScript.
We won't dive into the generated code itself, but let's see how we can use it.
Let's look at server.go.
func serverMain() {
if err := runServer(); err != nil {
fmt.Fprintf(os.Stderr, "Failed to run cache server: %s\n", err)
os.Exit(1)
}
}
func runServer() error {
srv := grpc.NewServer()
rpc.RegisterCacheServer(srv, &CacheService{})
l, err := net.Listen("tcp", "localhost:5051")
if err != nil {
return err
}
// blocks until complete
return srv.Serve(l)
}
type CacheService struct {
}
func (s *CacheService) Get(ctx context.Context, req *rpc.GetReq) (*rpc.GetResp, error) {
return nil, fmt.Errorf("unimplemented")
}
func (s *CacheService) Store(ctx context.Context, req *rpc.StoreReq) (*rpc.StoreResp,
error) {
return nil, fmt.Errorf("unimplemented")
}
func clientMain() {
if err := runClient(); err != nil {
fmt.Fprintf(os.Stderr, "failed: %v\n", err)
os.Exit(1)
}
}
func runClient() error {
// connnect
conn, err := grpc.Dial("localhost:5051", grpc.WithInsecure())
if err != nil {
return fmt.Errorf("failed to dial server: %v", err)
}
cache := rpc.NewCacheClient(conn)
// store
_, err = cache.Store(context.Background(), &rpc.StoreReq{Key: "gopher", Val: []byte("con")})
if err != nil {
return fmt.Errorf("failed to store: %v", err)
}
// get
resp, err := cache.Get(context.Background(), &rpc.GetReq{Key: "gopher"})
if err != nil {
return fmt.Errorf("failed to get: %v", err)
}
fmt.Printf("Got cached value %s\n", resp.Val)
return nil
}
Note: don't have to write networking code or serialization code.
Wait...
Is this just WSDL all over again?
Let's fill in the stubs that gRPC generated for us:
type CacheService struct {
store map[string][]byte
}
func (s *CacheService) Get(ctx context.Context, req *rpc.GetReq) (*rpc.GetResp,
error) {
val := s.store[req.Key]
return &rpc.GetResp{Val: val}, nil
}
func (s *CacheService) Store(ctx context.Context, req *rpc.StoreReq)
(*rpc.StoreResp, error) {
s.store[req.Key] = req.Val
return &rpc.StoreResp{}, nil
}
There's a number of error codes each corresponding to types of errors. It's kind of like HTTP errors, but no response body.
func (s *CacheService) Get(ctx context.Context, req *rpc.GetReq) (*rpc.GetResp, error) {
val, ok := s.store[req.Key]
if !ok {
return nil, status.Errorf(codes.NotFound, "Key not found %s",
req.Key)
}
return &rpc.GetResp{Val: val}, nil
}
There's a simple API for that. On the server:
func runServer() error {
tlsCreds, err := credentials.NewServerTLSFromFile("tls.crt", "tls.key")
if err != nil {
return err
}
srv := grpc.NewServer(grpc.Creds(tlsCreds))
rpc.RegisterCacheServer(srv, &CacheService{make(map[string][]byte)})
l, err := net.Listen("tcp", "localhost:5051")
if err != nil {
return err
}
return srv.Serve(l)
}
On the client:
func runClient() error {
// connect
// InsecureSkipVerify only for this example
tlsCreds := credentials.NewTLS(&tls.Config{InsecureSkipVerify: true})
conn, err := grpc.Dial("localhost:5051", grpc.WithTransportCredentials(tlsCreds))
if err != nil {
return fmt.Errorf("failed to dial server: %v", err)
}
protobuf serialized over HTTP/2:
There are 3 implementations at the moment:
Let's try Multitenancy (associating client ID with each request):
message StoreReq {
string key = 1;
bytes val = 2;
string account_token = 3; // <-- woo!
}
app.proto:
service Accounts {
rpc GetByToken(GetByTokenReq) returns (GetByTokenResp) {}
}
message GetByTokenReq {
string token = 1;
}
message GetByTokenResp {
Account account = 1;
}
message Account {
int64 max_cache_keys = 1;
}
client.go:
func runClient() error {
cache := rpc.NewCacheClient(conn)
// store
_, err = cache.Store(context.Background(), &rpc.StoreReq{
AccountToken: "inconshreveable",
Key:
"gopher",
Val:
[]byte("con"),
})
if err != nil {
return fmt.Errorf("failed to store: %v", err)
}
// get
resp, err := cache.Get(context.Background(), &rpc.GetReq{Key: "gopher"})
if err != nil {
return fmt.Errorf("failed to get: %v", err)
}
}
server.go:
type CacheService struct {
accounts rpc.AccountsClient
store map[string][]byte
keysByAccount map[string]int64
}
func (s *CacheService) Store(ctx context.Context, req *rpc.StoreReq) (*rpc.StoreResp, error) {
resp, err := s.accounts.GetByToken(context.Background(), &rpc.GetByTokenReq{
Token: req.AccountToken,
})
if err != nil {
return nil, err
}
if s.keysByAccount[req.AccountToken] >= resp.Account.MaxCacheKeys {
return nil, status.Errorf(codes.FailedPrecondition, "Account %s exceeds max key limit %d", req.A$
}
if _, ok := s.store[req.Key]; !ok {
s.keysByAccount[req.AccountToken] += 1
}
s.store[req.Key] = req.Val
return &rpc.StoreResp{}, nil
}
Now someone tells you your service is too slow. And here you realize you have no visibility. What do you do?
Option 1: add logging:
client.go:
func runClient() error {
// store
start := time.Now() // <==
_, err = cache.Store(context.Background(), &rpc.StoreReq{
AccountToken: "inconshreveable",
Key:
"gopher",
Val:
[]byte("con"),
})
log.Printf("cache.Store duration %s", time.Since(start))
if err != nil {
return fmt.Errorf("failed to store: %v", err)
}
// get
start = time.Now() // <==
resp, err := cache.Get(context.Background(), &rpc.GetReq{Key: "gopher"})
log.Printf("cache.Get duration %s", time.Since(start)) // <==
if err != nil {
return fmt.Errorf("failed to get: %v", err)
}
}
server.go:
func (s *CacheService) Store(ctx context.Context, req *rpc.StoreReq) (*rpc.StoreResp, error) {
start := time.Now()
resp, err := s.accounts.GetByToken(context.Background(), &rpc.GetByTokenReq{
Token: req.AccountToken,
})
log.Printf("accounts.GetByToken duration %s", time.Since(start))
if err != nil {
return nil, err
}
}
Note: this is a lot of boilerplate. Turns out gRPC has something for that: the client interceptor. Every time you make a remote call, the interceptor middleware will be invoked.
interceptor.go:
func WithClientInterceptor() grpc.DialOption {
return grpc.WithUnaryInterceptor(clientInterceptor)
}
func clientInterceptor(
ctx context.Context,
method string,
req interface{},
reply interface{},
cc *grpc.ClientConn,
invoker grpc.UnaryInvoker,
opts ...grpc.CallOption,
) error {
start := time.Now()
err := invoker(ctx, method, req, reply, cc, opts...) // <==
log.Printf("invoke remote method=%s duration=%s error=%v", method,
time.Since(start), err)
return err
}
client.go:
func runClient() error {
// connnect
tlsCreds := credentials.NewTLS(&tls.Config{InsecureSkipVerify: true})
conn, err := grpc.Dial("localhost:5051",
grpc.WithTransportCredentials(tlsCreds),
WithClientInterceptor()) // <==
if err != nil {
return fmt.Errorf("failed to dial server: %v", err)
}
}
server.go:
func runServer() error {
// client for accounts service
tlsCreds := credentials.NewTLS(&tls.Config{InsecureSkipVerify: true})
conn, err := grpc.Dial("localhost:5052",
grpc.WithTransportCredentials(tlsCreds),
WithClientInterceptor()) // <==
if err != nil {
return fmt.Errorf("failed to dial accounts server: %v", err)
}
accounts := rpc.NewAccountsClient(conn)
}
On the server side, there's a server interceptor.
interceptor.go:
func ServerInterceptor() grpc.ServerOption {
return grpc.UnaryInterceptor(serverInterceptor)
}
func serverInterceptor(
ctx context.Context,
req interface{},
info *grpc.UnaryServerInfo,
handler grpc.UnaryHandler,
) (interface{}, error) {
start := time.Now()
resp, err := handler(ctx, req)
log.Printf("invoke server method=%s duration=%s error=%v", info.FullMethod,
time.Since(start), err)
return resp, err
}
server.go:
func runServer() error {
// cache server
tlsCreds, err = credentials.NewServerTLSFromFile("tls.crt", "tls.key")
if err != nil {
return err
}
srv := grpc.NewServer(grpc.Creds(tlsCreds), ServerInterceptor())
rpc.RegisterCacheServer(srv, NewCacheService(accounts))
l, err := net.Listen("tcp", "localhost:5051")
if err != nil {
return err
}
return srv.Serve(l)
}
Server-side timeout:
server.go:
func (s *CacheService) Store(ctx context.Context, req *rpc.StoreReq)
(*rpc.StoreResp, error) {
accountsCtx, _ := context.WithTimeout(context.Background(), 2*time.Second)
resp, err := s.accounts.GetByToken(accountsCtx, &rpc.GetByTokenReq{
Token: req.AccountToken,
})
if err != nil {
return nil, err
}
if s.keysByAccount[req.AccountToken] >= resp.Account.MaxCacheKeys {
return nil, status.Errorf(codes.FailedPrecondition, "Account %s exceeds max
key limit %d", req.AccountToken, resp.Account.MaxCacheKeys)
}
}
Now you look in the logs you and find you're still failing SLA. Some round-trips take 2.2 seconds (more than 2 seconds). Why? Your timeout only covers a portion of the full request/response roundtrip.
So let the client set its own timeout:
client.go:
func runClient() error {
// store
ctx, _ := context.WithTimeout(context.Background(), time.Second)
_, err = cache.Store(ctx, &rpc.StoreReq{
AccountToken: "inconshreveable",
Key:
"gopher",
Val:
[]byte("con"),
})
if err != nil {
return fmt.Errorf("failed to store: %v", err)
}
// get
ctx, _ = context.WithTimeout(context.Background(), 50*time.Millisecond)
resp, err := cache.Get(ctx, &rpc.GetReq{Key: "gopher"})
if err != nil {
return fmt.Errorf("failed to get: %v", err)
}
fmt.Printf("Got cached value %s\n", resp.Val)
return nil
}
How does that interact with the timeout you set previously on the server? Simple: "the context propagates through."

Now let's say you want to call your service with a dry run flag. I want to run it without side effects. I want it to work on all mutable API.
This is simple with passing the right gRPC metadata (analogous to HTTP headers).

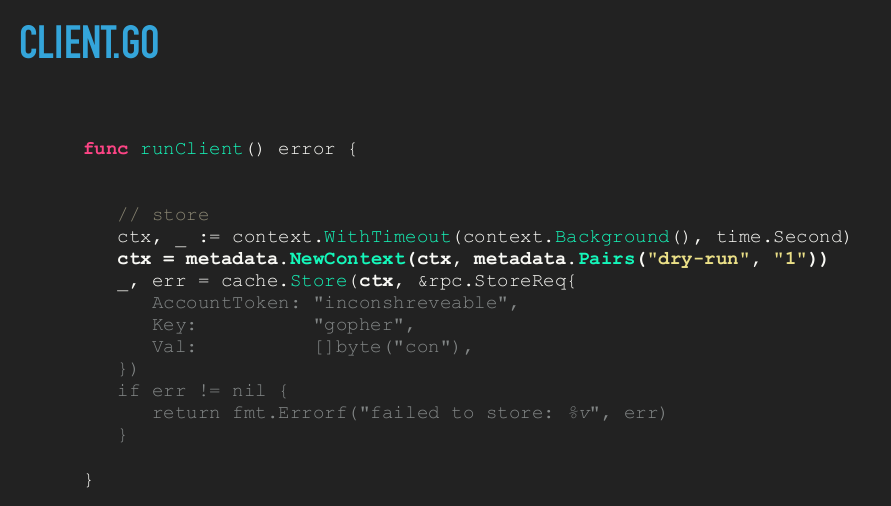
Let's add retry logic.

Idempotent logic? We can have safe retries:

But now failed operations are slow. What's going on?


In your response message, you add a new field that indicates whether it is possible to retry in the case of an error.
You really want a structured error, not just a code and string. You want a full object's worth of parameters.
Something like this:
message Error { int64 code = 1; string message = 2; bool temporary = 3; int64 userErrorCode = 4;}
Unfortunately, this gets a little messy... A lot of serialization and deserialization is required, since gRPC doesn't have response bodies.
This is one of the larger frustrations working with gRPC compared to HTTP.
Let's say you now want to add the ability to dump the contents of your cache service.
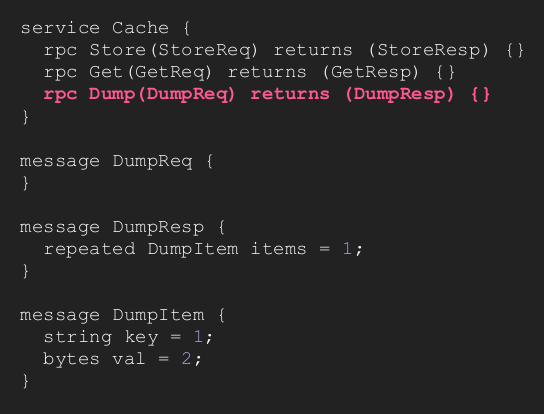
Now you run into non-enough memory errors. What defensive measures can you add?
Set max number of concurrent streams (simultaneous HTTP/2 streams per client):
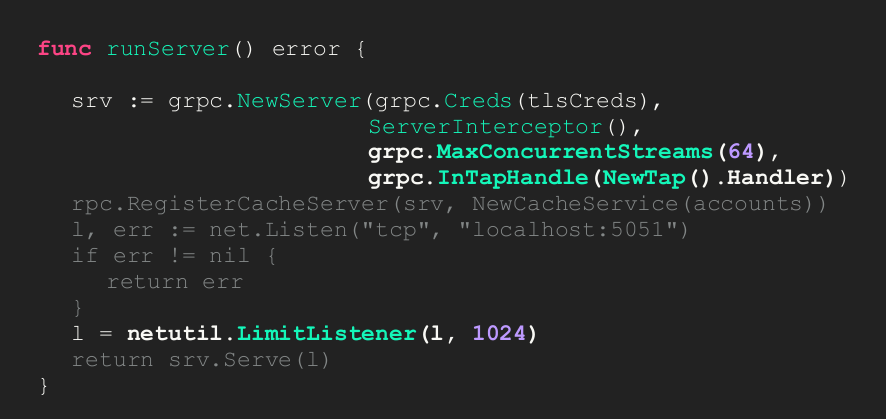
gRPC also lets you use an InTap handler, a piece of code just like the server interceptor, but happens a little bit earlier in request lifecycle.

But what if that doesn't solve all your memory issues?
app.proto:
syntax = "proto3";
package rpc;
service Cache {
rpc Store(StoreReq) returns (StoreResp) {}
rpc Get(GetReq) returns (GetResp) {}
rpc Dump(DumpReq) returns (stream DumpItem) {}
}
message DumpReq {
}
message DumpItem {
string key = 1;
bytes val = 2;
}
server.go:
func (s *CacheService) Dump(req *rpc.DumpReq, stream rpc.Cache_DumpServer) error {
for k, v := range s.store {
stream.Send(&rpc.DumpItem{
Key: k,
Val: v,
})
}
return nil
}
client.go:
func runClient() error {
// stream
stream, err := cache.Dump(context.Background(), &rpc.DumpReq{})
if err != nil {
return fmt.Errorf("failed to dump: %v", err)
}
for {
item, err := stream.Recv()
if err == io.EOF {
break
}
if err != nil {
return fmt.Errorf("failed to stream item: %v", err)
}
fmt.Printf("Cache Entry: %s => %s\n", item.Key, item.Val)
}
return nil
}
There's not enough time to go into detail, but one thing to note: The fact that you're establishing a single persistent connection means that every request you make goes to the same server.
So, you have to put the load-balancing logic in the client.
You can of course put this logic into a middleware server that does this for you, so the actual client doesn't have to worry about this. This is still pretty new, the spec is experimental.
Using your service from Python:
import grpc
import rpc_pb2 as rpc
channel = grpc.insecure_channel('localhost:5051')
cache_svc = rpc.CacheStub(channel)
resp = cache_svc.Get(rpc.GetReq(
The future of gRPC is easy to track: look at the grpc/grpc-proposals repository and grpc-io mailing list.

With Sourcegraph, the code understanding platform for enterprise.
Schedule a demo