Cheating is all you need
There is something legendary and historic happening in software engineering, right now as we speak, and yet most of you don't realize at all how big it is.

There is something legendary and historic happening in software engineering, right now as we speak, and yet most of you don't realize at all how big it is.
Heya. Sorry for not writing for so long. I'll make up for it with 3000 pages here.
I'm just hopping right now. That's kinda the only way to get me to blog anymore.
I've rewritten this post so many times. It's about AI. But AI is changing so fast that the post is out of date within a few days. So screw it. I'm busting this version out in one sitting.
(Spoiler alert: There's some Sourcegraph stuff at the end, including a product plug and some recruiting stuff. But >80% of this post is just about LLMs–GPT etc.–and you, a programmer.)
There is something legendary and historic happening in software engineering, right now as we speak, and yet most of you don't realize at all how big it is.
LLMs aren't just the biggest change since social, mobile, or cloud–they're the biggest thing since the World Wide Web. And on the coding front, they're the biggest thing since IDEs and Stack Overflow, and may well eclipse them both.
But most of the engineers I personally know are sort of squinting at it and thinking, "Is this another crypto?" Even the devs at Sourcegraph are skeptical. I mean, what engineer isn't. Being skeptical is a survival skill.
Remember I told you how my Amazon shares would have been worth $130 million USD today if I hadn't been such a skeptic about how big Amazon was going to get, and unloaded them all back in 2004-ish. Right? I told you about that? I'm sure I mentioned it once or twice. Not that I am bitter. No.
But did I ever tell you about the time AWS was just a demo on some engineer's laptop? No? Well it was Ruben Ortega and Al Vermeulen. They were walking around the eng department at Amazon, showing their "web service" demo to anyone who'd watch it. This was back in maybe… 2003? Ish? They showed us how you could make a service call over the web, like by hitting a URL and sending the right query parameters.
Well lo and behold we were skeptical. Why the hell would you make a service call over the web? That's not what it was even designed for! Not to mention, it obviously wouldn't perform as well as CORBA (Amazon's stupid-ass RPC system at the time). The whole thing just didn't make any sense to us.
We were seeing the first little flecks of lava from what would become a trillion-dollar volcano of money called AWS and Cloud Computing.
But a lot of us were skeptical. To most of us, those little lava flecks looked like fireflies.
I could tell you a LOT of stories like the web-services one. Great big shit always starts life as a demo.
What about chatting with people in a browser? Doesn't matter whether you're using Facebook, Google Chat, LinkedIn, or just chatting with a customer service agent: if you're having a conversation with someone in a browser, all that shit started life as a teeny demo of 2 engineers sending messages back and forth over a "hanging GET" channel back in 2005. Entire industries were built on that one little channel, and it wasn't even very good.
What about Kubernetes? I remember seeing a demo of that early on, on Brendan Burns' work laptop, when it was called mini-Borg. Entire industries are being built on Kubernetes, and it's not even very good either. 😉 Or look at Docker! Something as innocuous as linux cgroups, a little process-isolation manager, became the technical foundation for containers, which now utterly pervade our industry.
If you can build something as big as Amazon Web Services with a stack based on a simple service call, or whole social networks and customer service suites based on simple browser-to-browser communication, or a robust way of delivering and managing software based on a little process isolation code, then just imagine how big a thing you could build – bear with me here – if you had the goddamn Singularity as your starting point?
I mean, I joke, but… I mean… Right? I'm guessing you prolly missed it in OpenAI's 98-page GPT-4 technical report, but large models are apparently already prone to discovering that "power-seeking" is an effective strategy for increasing their own robustness. Open the PDF and search for "power-seeking" for a fun and totally 100% non-scary read.
You can build truly massive things by building upon little technical breakthroughs.
And folks, this technical breakthrough? It ain't little.
If you're not pant-peeingly excited and worried about this yet, well… you should be.
We did an internal poll at Sourcegraph: Do you have positive sentiment or negative sentiment about LLMs for coding? Options were Positive, Negative, and Meh. And lo, it was about ⅔ Meh or Negative (i.e., Skeptics), which I suspect is fairly representative of the whole industry.
I asked around, and even as of a couple weeks ago, some devs questioned whether ChatGPT could even write working code, let alone write a full program by simply by telling it to write it.
So here I am, talking about money volcanoes, and my coworkers have formed a huge whirling meh-nado. Which natural disaster should you believe?
Well I mean, I guess a demo is worth a thousand mehs. Let's try it out.
Let's have ChatGPT write some Emacs-Lisp code. I'm picking emacs-lisp because it's a corner case language, bit of a stress test for the LLM, and because it's easy for me to try it out interactively.
OK. I just typed this prompt into ChatGPT:
> Write an interactive emacs-lisp function that pops to a new buffer, prints out the first paragraph of "A tale of two cities", and changes all words with 'i' in them red. Just print the code without explanation.

Here's the code it spat out, if you can't read the screenshot:
(defun display-tale-of-two-cities ()
(interactive)
(let ((text "It was the best of times, it was the worst of times, it was the age of wisdom,
it was the age of foolishness, it was the epoch of belief, it was the epoch of incredulity,
it was the season of Light, it was the season of Darkness, it was the spring of hope, it was
the winter of despair, we had everything before us, we had nothing before us, we were all
going direct to Heaven, we were all going direct the other way – in short, the period was so
far like the present period, that some of its noisiest authorities insisted on its being
received, for good or for evil, in the superlative degree of comparison only."))
(pop-to-buffer "*A Tale of Two Cities*")
(erase-buffer)
(insert text)
(goto-char (point-min))
(while (re-search-forward "\\b\\w*\\i\\w*\\b" nil t)
(add-text-properties
(match-beginning 0) (match-end 0)
'(face (:foreground "red"))))))
I copied this code directly into my Emacs session and ran it, and it did exactly what I asked it to do:

As you can see from the screenshot, I ran the command and it opened a buffer, printed the requested text, and then turned all the words containing 'i' red.
In one shot, ChatGPT has produced completely working code from a sloppy English description! With voice input wired up, I could have written this program by asking my computer to do it.
And not only does it work correctly, the code that it wrote is actually pretty decent emacs-lisp code. It's not complicated, sure. But it's good code.
Of course people have done much, much fancier things than this. Someone wrote a product description on a napkin, took a picture, and GPT wrote a working web app that implements the product description on the napkin in the picture. The amount of power here is honestly unknown; it's more like a cavern that we haven't fully explored. And it just gets deeper as the LLMs get bigger.
I mean, this stuff is unbelievably powerful. And yet I am persistently met with a mixture of disbelief and pearl-clutching. Argh, the pearl-clutching! Don't even get me started on the pearl-clutching. Oh look, now you've got me started.
Okay, you asked for it.
One of the craziest damned things I hear devs say about LLM-based coding help is that they can't "trust" the code that it writes, because it "might have bugs in it".
Ah me, these crazy crazy devs.
Can you trust code you yeeted over from Stack Overflow? NO!
Can you trust code you copied from somewhere else in your code base? NO!
Can you trust code you just now wrote carefully by hand, yourself? NOOOO!
All you crazy MFs are completely overlooking the fact that software engineering exists as a discipline because you cannot EVER under any circumstances TRUST CODE. That's why we have reviewers. And linters. And debuggers. And unit tests. And integration tests. And staging environments. And runbooks. And all of goddamned Operational Excellence. And security checkers, and compliance scanners, and on, and on and on!
So the next one of you to complain that "you can't trust LLM code" gets a little badge that says "Welcome to engineering motherfucker". You've finally learned the secret of the trade: Don't. Trust. Anything!
Peeps, let's do some really simple back-of-envelope math. Trust me, it won't be difficult math.
How much of a productivity increase is that? Well jeepers, if you're only doing 1/5th the work, then you are… _punches buttons on calculator watch_… five times as productive. 😲
When was the last time you got a 5x productivity boost from anything that didn't involve some sort of chemicals?
I'm serious. I just don't get people. How can you not appreciate the historic change happening right now?
OK time to get concrete. I'm already on page 7, and my last attempt at this blog ran 25+ pages and languished for weeks.
Let's finish this.
OK sooooo… this is the part that went on for 20 pages before, so let's just make it reeeeeal simple. One paragraph.
Here is everything you need to know about the history of LLMs, for our purposes today:

Congrats, you're all caught up on the history of LLMs. Go watch this amazing video for how to implement it in Python.
OK now we can talk coding assistants. They're just a thing that sits in your IDE and they talk to the LLM for you.
Depending on the particular assistant, they can read and explain code, document code, write code, autocomplete it, diagnose issues, and even perform arbitrary IDE tasks through "agents" that give the LLM robotic powers, including the ability to wield and target laser guns, if someone wants to put in the work. Some assistants also understand your project environment and can answer questions about build targets, branches, your IDE, etc.
So, already pretty cool. Right?
But now they are beginning to be able to perform more complex tasks, such as generating a PR from the diffs on the current branch, including a detailed commit message summarizing the changes.
Some assistants have a conversational/chat interface, too. This kind can do everything a bot like ChatGPT can do, like drafting emails, or answering random questions about the code base or the environment.
I personally prefer a coding assistant with a chat interface. In part because I can type, but also because it makes them a platform. I can build my own workflows. Bonus points if they expose the underlying platform bits with APIs.
I guess the simplest way to think about it would be a sort of "real-time in-IDE Stack Overflow" coupled with a really powerful new set of boilerplate automation tasks.
OK, congrats again – you're up to speed on what LLM-based coding assistants can do. It's… pretty much anything. You could hook it up to outbound email and tell it to sell itself. Sky's the limit. At this point we're more limited by imagination than by technology.
So! Yeah. Coding assistants. I hope by now you get how powerful they're going to be. They may take different shapes and forms, but they're all going to be incredibly badass before very much longer.
Let's dig a little into how they understand your personal code, and then we're ready to party. 🎉
LLMs are trained on an absolutely staggering amount of data… but that doesn't include your code.
There are two basic approaches to making the LLM smarter about your code. The first is to fine-tune (or train) on your code. This is not a business model that has been fully fleshed out yet, but it's coming. And importantly it's only part of the picture.
The other way is to bring in a search engine. You can think of it as three related scenarios:
You talk to LLMs by sending them an action or query, plus some relevant context. So for instance, if you want it to write a unit test for a function, then you need to pass along that whole function, along with any other relevant code (e.g. test-fixture code) so that it gets the test right.
That context you send over is called the context window, and I think of it as the "cheat sheet" of information that you pass along as part of your query.
And folks, it ain't much. It's almost exactly like a 2-sided index card vs your whole textbook, for an exam. They give you between 4k and 32k tokens of 3-4 characters each, so at best, maybe 100k of text, to input into the LLM as context for your query. That 100k cheat sheet is how you tell the LLM about your code.
In an ideal world, you'd just pass your entire code base in with each query. In fact, Jay Hack just tweeted a graph showing how the latest context window size in GPT-4 compares to some popular code bases:
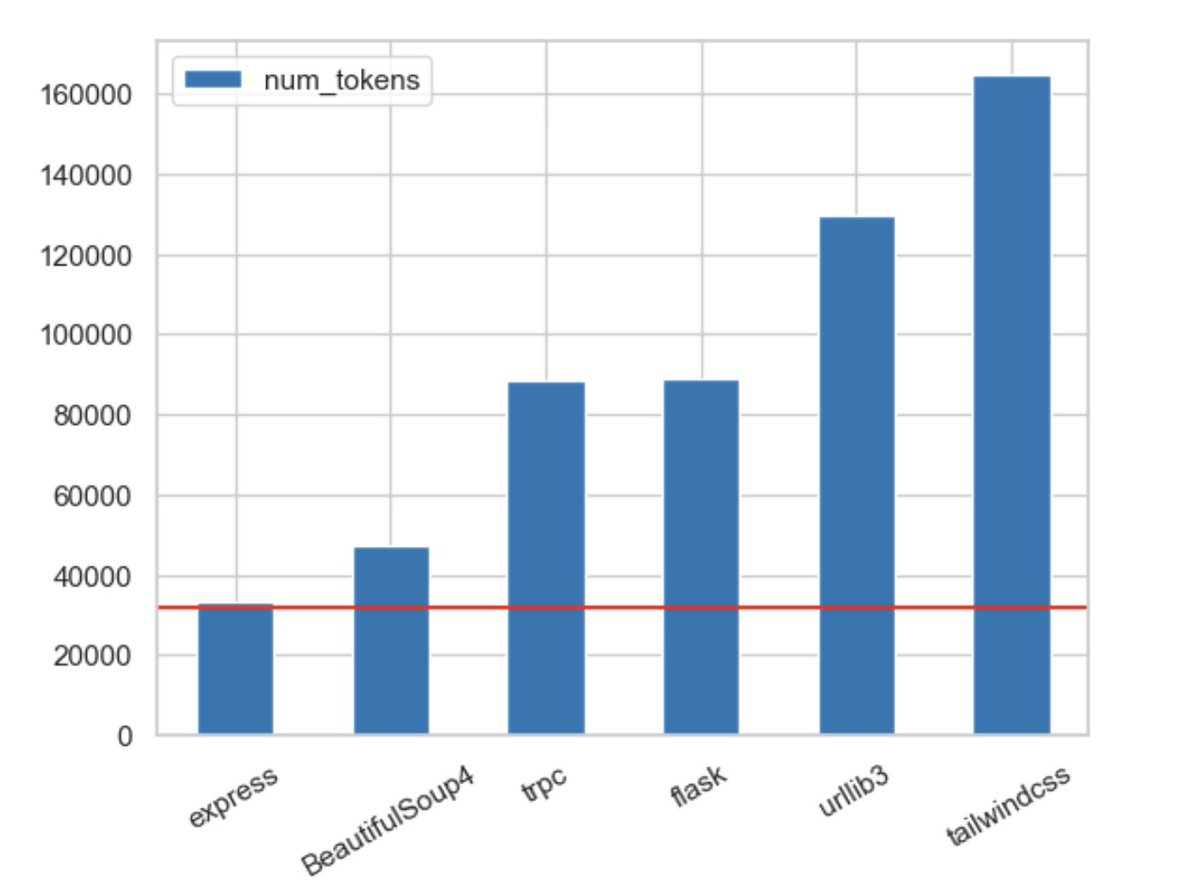
Which is kind of exciting… until you realize that it's still just incredibly tiny compared to real-world code bases. It's an index card vs a textbook… just a slightly bigger index card.
That cheat sheet is all you get. That's how you talk to an LLM. You pass it a cheat sheet.
Which means what goes ON that cheat sheet, as you can probably imagine, is really really important.
And with that, friends, we are finally ready for the punchline, the party, and the demo.
You made it!
There are, by my last count, approximately 13 hillion frillion jillion LLM-backed coding assistants out there, as of mid-March. But they are all in a desperate race to the bottom, because they're all using the exact same raw materials: An LLM, your IDE, your code base, and that pesky little context window.
Nobody can differentiate on the LLM; they're all about the same. And the IDE and your code base are the same. All they can try to differentiate on is their UI and workflows, which they're all going to copy off each other. Good for you, bad for them.
The punchline, and it's honestly one of the hardest things to explain, so I'm going the faith-based route today, is that all the winners in the AI space will have data moats.
A "data moat" is, in a nutshell, having access to some data that others do not have access to.
You need a data moat to differentiate yourself in the LLM world.
Why? Because the data moat is how you populate the context window ("cheat sheet").
If you can't feed the LLM your whole code base, and you can only show it 100k characters at a time, then you'd better be really goddamn good at fetching the right data to stuff into that 100k-char window. Because that's the only way to affect the quality of the LLM's output!
Put another way, you need a sidecar database. The data moat needs to be fast and queryable. This is a Search Problem!
This is true even outside the world of engineering. There are probably 13 hillion jillion killion LLM-based outbound sales products being built like right now, as you're reading this. But only Salesforce and a few other companies with big data moats are going to be able to differentiate in that space.
OK! You're finally done learning stuff. I'm very proud that you've made it to the end.
The rest is a private Sourcegraph party. I mean, you can come along if you like, because you're a friend. I'll slip you by the door guy.
You've just graduated from Stevey's LLM Mini-U, and you have all the necessary theoretical background to appreciate why I feel I am the luckiest damn person on Earth, and why I'm throwing a party, right here on page two thousand eight hundred and ninety six of this blog post.
Because folks, I honestly don't know how I got so lucky. I joined Sourcegraph in September, not half so much for their product itself as for their Code Intelligence Platform, which was like the one I built back at Google. They'd nearly finished building v1 of this platform and it was ready to start powering something amazing.
And then LLMs landed 10 weeks after I joined. The Singularity, the Cloverfield monster stomping around eating people, and everything else that's happened since November 30th. Crazy town.
And what do LLMs need again? You, in the front row. Yeah, you.
They need the data moat! The sidecar database. For populating the cheat sheet. Remember?
It's a Search problem. And Sourcegraph has spent the past ten years building the solution.
Go figure.
Sourcegraph's platform has four enduring, difficult-to-reproduce dimensions that are incredibly relevant to the coding-assistant space:
Sourcegraph's engine powers gigantic enterprises with literally a hundred thousand git repositories, and/or multi-terabyte massive megarepos that make IDEs fall over and puke. And at its core is an engine so powerful that maybe teaming up with an AI was its destiny all along.
Whoo boy. Did I get lucky? I think I got pretty lucky. We have such an incredible head-start in this race.
When I say "We're building a coding assistant", I want you to think back to when Ruben Ortega showed us Amazonians his little demo of a remote procedure call over HTTP. That was Baby AWS.
Now take a look at what my esteemed colleague and Sourcegraph teammate Dominic Cooney slacked me last week:
In other news, I am getting even more enthusiastic. There is more, much more, to this space than LLMs and I think we have the embryonic stage of some amazing invention here. Like some realizations that context provisioning is a service. That the output has streams, like one into the editor and one into the chat. That the LLM benefits from the opportunity to self criticize. That the UX needs diffs and in-situ things to home in on things. That search is as big a deal as chat. Many of our thumbs down reactions to [LLMs] come from them complaining they didn't have the context of what language, file, codebase, etc. the user is talking about. Which bodes well because Sourcegraph should be able to do that really well.
He's glimpsed the future, and it's vast. His comment, "I think we have the embryonic stage of some amazing invention here", reminded me of all the embryonic stages I've seen of other eventually-amazing things: The Mosaic web browser. The mini-Borg demo that became Kubernetes. The Amazon web-services demo. The hanging-GET request in the browser.
Little things grow up, folks!
I've seen this movie before. I know how it ends. This volcano is the big one. Skeptics beware. At the very least, I hope by now you're taking LLM-backed coding assistants in general just a teeny bit more seriously than you were an hour ago.
OK, you've heard the punchline, and the party's in full swing. Lemme show you Cody and we'll call it a day.
Say hi to Cody:

Cody is Sourcegraph's new LLM-backed coding assistant. Cody knows about your code. It has templated actions, such as writing unit tests, generating doc comments, summarizing code, that kind of thing. You know. Stuff you can choose from a menu. Like other assistants. It even has code completions, if you're into that sort of thing.
Cody is not some vague "representation of a vision for the future of AI". You can try it right now.
And it has a chat interface! Which means it's totally open-ended; you can ask it any question at all about your code base or your environment, and we'll send it the right cheat sheet. And Cody itself is a platform, because you can use it to build your own LLM-backed workflows.
My favorite kind. Naturally.
Currently Cody is a VSCode plugin, though we'll have it in other places soon enough.

Cody scales up to the very biggest code bases in the world. And even though Cody is still a baby, just like Baby AWS back on Ruben's stinkpad in 2003, it's already able to lift a huge space rhino using only the power of the Force. Hang on, sorry wrong baby.
Ahem. As I was saying, like Baby AWS, Cody is also a baby with special powers, and honestly… we don't know how powerful it's going to get. It seems to be accelerating, if anything.
Oh, and anyone can sign up to get access start using Cody now. (Edited after Cody was released.)
OK so anyway here's how Cody works:

Here's the diagram above, in a nutshell:
And of course this is all just the veeeery beginning. This thing will grow into a goliath that enhances everything you do as an engineer.
Other coding assistants, which do not have Sourcegraph for Step 2 (populating the context), are stuck using whatever context they can get from the IDE. But sadly for them, IDEs weren't really designed with this use case in mind, and they make it difficult. And more damningly, no IDE scales up to industrial-sized code bases.
So it's just plain unfair. I'm just gonna call it like it is. Sourcegraph has an absolutely unfair advantage, which they built up over ten years of building out this incredibly scalable, precise, and comprehensive code intelligence platform, powered by a world-class search engine and code knowledge graph.
Did I mention I'm lucky? I'm so fortunate to be here, and grateful to be part of this team.
I don't really know how to finish this post. Are we there yet? I've tried to write this thing 3 times now, and it looks like I may have finally made it. I aimed for 5 pages, deliberately under-explained everything, and it's… fifteen. Sigh.
But hopefully you got the main takeaways. Baby AWS. Knee jerking. Meh-nadoes. Cheat sheets. Data moats. Cody. You got this!
LLMs aren't some dumb fad, like crypto. Yes, crypto was a dumb fad. This is not that.
Coding assistants are coming. They're imminent. You will use them this year. They will absolutely blow your mind. And they'll continue to improve at an astonishing rate.
They will feel gloriously like cheating, just like when IDEs came out, back in the days of yore. And for a time-constrained developer like me–and I say this as someone who has written over a million lines of production code…
Cheating is all you need.
Thanks for reading, and if you like, come be our Head of AI! Or come do something else with us! It's pretty merry around here already, but the more, the merrier.

With Sourcegraph, the code understanding platform for enterprise.
Schedule a demo