Agentic Coding in 2026: A Practical Guide for Big Code
Learn what agentic coding is, how AI coding agents work in real engineering orgs, and how to give them the codebase context they need to ship safely.

Learn what agentic coding is, how AI coding agents work in real engineering orgs, and how to give them the codebase context they need to ship safely.
Something shifted in 2025. AI coding tools went from suggesting the next line of code to writing whole pull requests, running the unit tests, and opening the next one. The label that stuck was "agentic coding," and by mid-2026, many large engineering organizations were experimenting with at least one agentic coding workflow, whether through IDE assistants, background coding agents, PR agents, or internal tools. The trouble: techniques that work on a side project fall over the moment you aim them at a 2,000-repository monorepo with twelve years of accumulated decisions.
This guide is for senior engineers and platform leaders making agentic coding work at real scale. We'll define the term, separate it from "vibe coding," walk through how the loop executes, and spend most of our time on why agents quietly break at the 80% mark and what context infrastructure stops that from happening.
Agentic coding is software development where an autonomous AI agent plans, writes, tests, and iterates on code with limited human intervention, using tools (a shell, a test runner, code search, and version control) to complete complex tasks across the development environment. Instead of typing every line and accepting one suggestion at a time, the developer describes an outcome, and the agent runs a loop until the outcome is reached or it gets stuck.
That definition draws a line that other AI coding categories don't cross. Autocomplete predicts the next token. Chat answers a question. AI agents take actions: they read files, call tools, run commands, observe outputs, and decide what to do next. By 2025, Anthropic, OpenAI, Google, GitHub, and others had moved from autocomplete and chat toward agentic workflows that can inspect repositories, run commands, call tools, and propose pull requests. Sourcegraph's CodeScaleBench work focuses on measuring how agents perform on large-codebase and multi-repo tasks, where retrieval quality affects execution time, retries, and cost.
The simplest way to feel the difference: watch what each tool does when you say "fix the failing build."
The behavioral leap is autonomous tool use: the agent decides what to do next based on what it just observed, the same way a human engineer does.
"Vibe coding" was coined by Andrej Karpathy in a February 2025 tweet describing "a new kind of coding" where you "fully give in to the vibes, embrace exponentials, and forget that the code even exists." Karpathy was honest about the scope. He was talking about throwaway weekend projects.
The term escaped that container immediately. By the end of 2025, it was Collins Dictionary's Word of the Year, applied to everything from prototype tinkering to production deploys. That's where the confusion starts, and why senior engineers bristle when the two terms get mashed together.
Vibe coding is a posture: trust the model, don't read the diff, keep prompting until it works.
Agentic coding is an architecture: the model is wired into tools, runs in a loop, and produces code that a human reviews against a definition of done.
The difference is who owns correctness. Simon Willison's writing on agentic engineering frames the practice as professional engineers using coding agents to amplify existing expertise, not replace human judgment with vibes. Vibe coding works when the cost of being wrong is zero. Agentic coding has to work when the cost of being wrong is a customer outage.
| Dimension | Vibe coding | Agentic coding |
|---|---|---|
| Human role | Trusts the model, ships if it runs | Reviews the diff, owns correctness |
| Code review | Optional, often skipped | Mandatory, often automated as a gate |
| Verification | "Looks like it works" | Tests, types, CI, sometimes a second agent |
| Best fit | Throwaway prototypes, side projects | Production code in a maintained repo |
| Failure mode | Bad code shipped without anyone noticing | Bad code caught at PR review or in CI |
If your team ships into a codebase other people maintain, you're doing agentic coding whether you call it that or not. Treating the agent's output as code that needs review, not as a finished product, is the line.
Every agentic coding system runs a variation of the same loop:
What makes one agent better than another is rarely the model. Many tools draw from the same frontier model families, so the differentiator is often the system around the model: retrieval, tool use, planning, sandboxing, and review. What varies most is how good each step of that loop is, especially step two.
Context gathering is where most of an agent's output quality is won or lost. A model can only reason about code it can see. If the agent searches the local working directory and finds three relevant files, it plans on three files. If the real change affects 17 files across 9 repositories, the agent doesn't know and won't ask. It produces confident, locally correct code that misses two-thirds of the work.
This is the difference between approximate retrieval (embeddings, vector similarity, "files that look related") and deterministic search (exact symbol references, every callsite, every interface implementer). Approximate retrieval is fine on a small repo. On Big Code, it returns plausible-looking results that miss cross-cutting impact, and the agent ships plausible-looking code with latent bugs.
Modern agents delegate. A planner decides what needs to happen, then spins up multiple agents to handle independent slices: one writes the migration, one updates unit tests, one drafts docs. Stripe's internal "Minions" workforce, described by Alistair Gray, follows the same shape: many small agents coordinated by shared context.
Sub-agents amplify whatever context layer the parent has. Bad context yields parallel wrong answers faster.
Here is the pattern anyone running agents at scale recognizes. The agent finishes a task in five minutes, the diff looks clean, the tests pass, and you merge it. Three days later, an unrelated team's CI starts failing because a downstream service still expects the old function shape, and your agent had no idea that service existed.
This is the 80% problem. AI coding agents reliably do the visible 80% of a task and miss the invisible 20% that lives outside their context window. The missed 20% is the same categories every time: auth middleware wrapping the changed function, API DTOs serialized at a different layer, audit logs recording state transitions, integration tests in a sibling repo, frontend guards mirroring backend permissions, and migration scripts that need regenerating.
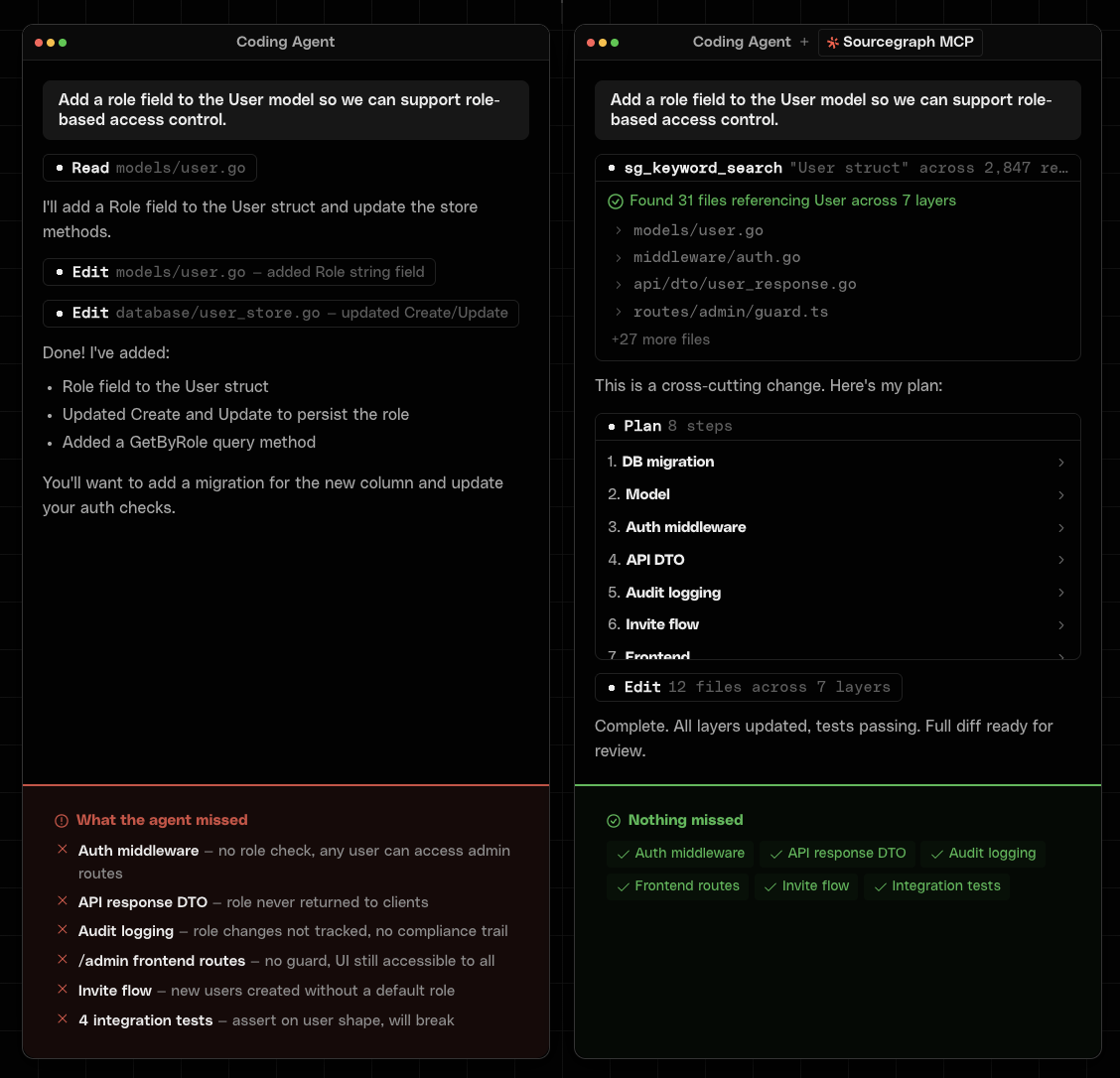
In the illustration above, an agent without full codebase context edits models/user.go and the store, declares done, and misses five things: auth middleware that doesn't check the new role, an API DTO that never returns it, the audit logging path, the frontend admin guard, and the invite flow that creates users without a default role. With cross-repo search spanning the full estate of repositories, the same task surfaces references across multiple layers, and the agent edits the additional files it would otherwise have missed. The agent didn't get smarter. It got more eyes.
This paradox of agentic coding generating more code is borne out in practice: we found that 84% of large enterprise accounts saw a steady increase in lines of code after AI rollout, and developers responded by searching more, not less. The agent's productivity ceiling is set by what it can see, and on Big Code, what it sees by default is a fragment.
The 80% problem isn't a model limitation. It's a context infrastructure problem that shows up in three ways:
If your team is hitting these and blaming the model, you're debugging the wrong layer.
The teams getting the most from agentic coding aren't the ones with the most expensive models. They're the ones with disciplined workflows that play to agent strengths and design around weaknesses. A useful baseline:
Steve Yegge's brute squad framing captures the new developer role in an agent-led workflow: less typing code, more steering and verifying many concurrent runs. The work doesn't disappear. It moves up a level.
| Phase | Without codebase context | With full codebase context | Risk addressed |
|---|---|---|---|
| Scoping | Engineer guesses blast radius | Search shows every call site up front | Underestimating cross-cutting impact |
| Planning | Agent plans on visible files only | Agent plans across all dependent layers | Missed integrations |
| Execution | Edits one or two repos | Edits all affected repos as one unit | Partial rollouts |
| Testing | Local tests pass | Sibling-repo integration tests included | Late CI failures |
| Review | Reviewer rebuilds context manually | Reviewer sees the same scoped graph | Slow, error-prone PR review |
| Audit | Hard to reconstruct what changed | Code Insights tracks adoption over time | Blind compliance gaps |
A useful pattern: when an agent says it's done, search the codebase for any other usage of the symbols it touched. If something turns up that the agent never opened, the task isn't done.
The 2026 agentic coding stack splits into three layers, and most teams use something from each. A category sketch, not a buyer's guide:
Coding agents run the loop. Common options include Anthropic's Claude Code, OpenAI Codex, GitHub Copilot's agentic workflows, Google's Gemini CLI, Amp, and open-source autonomous agents. They differ in model defaults, execution environment, sub-agent design, and how they handle context beyond the local workspace.
IDE integrations and chat assistants are AI tools that generate suggestions and answer questions in the editor. They're useful for short-horizon tasks but not autonomous in the loop sense.
Context and infrastructure layers are the substrate that makes AI agents work in a large org: indexing, code search, code intelligence, repository-wide knowledge. The Model Context Protocol (MCP), introduced by Anthropic in late 2024, is an emerging interface that gives compatible AI agents a standard way to request context from tools and systems that expose MCP servers.
A useful mental model: agents are the engine, MCP is the wiring, codebase context is the fuel. A great engine on bad fuel still stalls.
If the 80% problem is a context problem, solving it means giving every agent the same view of the codebase a tenured engineer has on day 1,000. This is what Sourcegraph is built for, and it plugs into whichever coding agent your team has standardized on, whether that's Claude Code, Gemini CLI, or another option.
Sourcegraph indexes every repository across your code hosts (GitHub, GitLab, Bitbucket, Gerrit, Perforce, Azure DevOps) into a unified, deterministic search corpus, available to humans through the UI and to agents through these surfaces:
None of this competes with Claude Code, Codex, Gemini CLI, or any other agent. It sits underneath them. As Sourcegraph's post on why code search at scale is essential lays out, coding agents optimize for the code you're writing, while enterprises need visibility into all the existing code. Teams that want a unified product use Amp; teams standardized on Claude Code, Codex, or Gemini CLI can wire in the MCP server without changing the agent.
Honesty caveat: on a small single-repo project, you don't need this codebase-wide context. Sourcegraph's value shows up the moment your repo count crosses 1 and accelerates towards 100.
The narrative that AI is going to make engineering disappear keeps getting louder, and the day-to-day reality keeps drifting in a different direction. Coding agents write code that ships, but they miss in predictable ways, and at Big Code scale, those misses compound into outages and silent debt unless you build context infrastructure underneath them.
The takeaway: agentic coding's productivity ceiling is set by context, not model quality. Pick the agent your team trusts, then invest the same energy in the substrate that gives it a complete view of the codebase. That's where the cost savings, the speed gains, and the difference between merging cleanly and breaking three downstream services actually live.
If you're past the toy-repo phase, see how Sourcegraph gives coding agents complete codebase context and book a demo to see it wired into your stack.
What is agentic code?
Agentic code is code produced by an autonomous AI agent that plans, writes code, and tests software through a tool-using loop, rather than by a developer accepting one suggestion at a time. The term covers both the resulting code and the practice of building software this way.
What is the difference between vibe coding and agentic coding?
Vibe coding is a casual posture (trust the model, ship if it runs, skip the diff) coined by Andrej Karpathy for prototypes. Agentic coding is an engineering practice: an autonomous agent runs a "plan, write, test, refine" loop, and a human reviews the diff against real acceptance criteria. Vibe coding optimizes for speed on disposable work. Agentic coding optimizes for production code with the same code review discipline you'd apply to a human pull request.
What is the 80% problem in agentic coding?
The 80% problem is the pattern where coding agents reliably complete the visible 80% of a task and silently miss the 20% outside their context window: cross-cutting changes, sibling repos, auth middleware, audit logging, integration tests, frontend guards. The fix isn't a better model; it's giving the agent a deterministic, repository-wide view of the codebase so the invisible 20% becomes visible before it ships.
How expensive is agentic coding?
Costs break into model inference, retrieval, and indexing infrastructure, and human review time. Inference is the most volatile line item because agents make many calls per task during the refine loop. Teams report wide variance depending on context quality: with the right context, agents retry less and finish faster. Benchmarks like Sourcegraph's CodeScaleBench focus on how that retrieval quality plays out on large-codebase and multi-repo tasks.

With Sourcegraph, the code understanding platform for enterprise.
Schedule a demo