Automated code review used to mean a linter catching a missing semicolon. Over the last few years (and especially in 2026), the category is broader and with a lot more capabilities. Static analyzers still enforce deterministic rules, but AI reviewers can go way beyond that, helping to summarize diffs, flag semantic issues, and sometimes reason across repo context. Most teams rarely choose one or the other and instead tend to combine static analysis for high-confidence gates and AI review for earlier, more contextual feedback before merge.
This roundup compares 13 review tools based on public documentation, product demos, and experience where available, and the criteria we see matter most in large engineering organizations.
What Are Automated Code Review Tools?
In the most high-level explanation, automated code review tools analyze a pull request without a human in the loop and surface findings that the author should fix before merging. The category covers two distinct approaches.
Rule-based static analysis parses source code, builds syntax or semantic representations, and matches code against rules, data-flow checks, or policy patterns. A static analysis tool is strongest at deterministic findings: security issues, duplication, complexity, style violations, and policy checks. SonarQube, Semgrep, and the open-source linter family (ESLint, Pylint, RuboCop) live here. The output is deterministic, which makes these tools the right substrate for compliance gates and regulated environments.
AI-powered code review sends the diff (and, in better tools, the surrounding repo context) to an LLM-backed agent that produces semantic feedback: "this function silently swallows the timeout error two callers depend on," not "missing return type." CodeRabbit, Qodo, and Greptile sit in this camp. An AI code review tool can catch context-dependent issues that simple lint rules miss, although it is also more variable and harder to use as a hard compliance gate.
How We Evaluated These Tools
The criteria below reflect what matters when a tool has to survive contact with a 5,000-engineer org.
- Signal-to-noise ratio. A code review tool that posts 18 comments per pull request teaches reviewers to ignore it. We weighted the false positive rate heavily.
- Integration depth. Does it post inline comments, block merges, run on schedules, or expose an API? A bot that only writes a single summary comment is doing 20% of the job.
- Monorepo support. Many tools degrade above a few hundred MB of source. We noted which stayed accurate, which timed out, and which silently truncated context.
- Repo-wide context. An AI reviewer that only sees the diff cannot tell you that the function you just changed has 14 callers in three other services. Tools that can pull context from across the codebase produced materially better feedback.
- Pricing transparency. We discounted tools with "contact sales" as the only signal.
Although other code review tools exist, these are some of the most popular tools out there that help teams to review code effectively based on our above criteria.
Comparison Table, At a Glance
| Tool |
Type |
Best for |
Free tier |
Monorepo support |
Pricing model |
| Qodo |
AI |
Multi-agent review with test generation |
Yes, individual/free path |
Strong (Context Engine) |
Per seat |
| CodeRabbit |
AI |
High-volume PR commenting on GitHub/GitLab |
Yes; free plan and OSS support |
Moderate |
Per developer |
| Greptile |
AI |
Codebase-graph reviews on a single repo |
No published free Cloud tier |
Strong (single-repo) |
Per developer |
| GitHub Copilot Code Review |
AI |
GitHub-native teams |
Eligible Copilot plans; verify usage |
Moderate |
Per user (Copilot) |
| Sourcegraph (Code Search + MCP) |
Code context / intelligence layer |
Big Code, multi-repo, agent-driven workflows |
Platform pricing varies |
Designed for it |
Platform + per-user |
| SonarQube / SonarCloud |
Static |
Enterprise code quality gates and compliance |
Community edition |
Strong |
Per LOC / per user |
| Codacy |
Static |
Mixed-stack code quality + security in one UI |
Yes |
Moderate |
Per seat |
| Semgrep |
Static |
Custom security rules and SAST policy |
Yes (OSS engine) |
Strong |
Per developer |
| DeepSource |
Static |
Polyglot code quality + autofix pull requests |
Limited |
Moderate |
Per developer |
| Snyk Code |
Static (security) |
Security-focused SAST and SCA |
Yes |
Moderate |
Per developer |
| ESLint / Pylint / RuboCop / PMD |
OSS linters |
Per-language style and bug rules |
Free (OSS) |
Yes |
Free |
| Reviewdog |
OSS glue |
Posting any linter's output as PR comments |
Free |
Yes |
Free |
| Danger |
OSS rules engine |
PR-level policy checks (no AST) |
Free |
Yes |
Free |
Top AI-Powered Code Review Tools
AI reviewers vary widely in how much repo context they can see and how they integrate with existing pull request workflows. The five below are the ones we see most often in production.
Qodo

Qodo (formerly CodiumAI) is an AI code reviewer with built-in unit test generation, organized as a multi-agent system on top of GitHub, GitLab, Bitbucket, and Azure DevOps.
Key capabilities
- Severity-categorized PR feedback from separate agents for bug detection, security, code quality, and test coverage
- Unit test generation for untested code paths, attached as PR comments
- Repo-aware suggestions via Qodo's Context Engine
- IDE extensions for VS Code and JetBrains alongside the PR bot
Pricing
- Developer: free; 75 IDE/CLI credits, community support
- Teams: $30 per user per month; 20 PRs and 2,500 credits per user
- Enterprise: custom; required for self-hosted, on-prem, or air-gapped deployments
Pros
- Test generation in the PR thread closes a gap most reviewers leave open
- Broad VCS coverage out of the box
- Free Developer tier is workable for solo evaluation
Cons
- Comment volume can balloon without severity tuning
- Self-hosting only on Enterprise
- Surface area is split between Qodo Merge and the IDE extensions
CodeRabbit

CodeRabbit is an AI reviewer that posts structured PR summaries plus line-by-line comments and bundles 40+ open-source linters and SAST scanners alongside its own LLM-based review.
Key capabilities
- PR summary plus inline review comments on GitHub, GitLab, Bitbucket, Azure DevOps
- One-config orchestration of static tools (Semgrep, Bandit, ESLint, and others)
- Repo-level "Learnings" that adjust feedback based on prior review interactions
- CodeRabbit IDE plugin for pre-PR checks in VS Code and JetBrains
Pricing
- Free: PR summaries plus a 14-day Pro trial
- Pro: $24 per developer per month annually, or $30 monthly
- Pro Plus: $48 per developer per month annually
- Enterprise: custom
- OSS plan: free for open-source projects
- Usage-based credit add-on for unrestricted CLI/PR reviews
Pros
- Replaces the work of wiring multiple linters into PR comments
- Multi-VCS support and an OSS plan lower the trial barrier
- Customizable review tone and learned preferences over time
Cons
- Mostly sees the diff plus a small surrounding window; weaker on cross-repo context
- Comment density can get noisy on large PRs
- Per-developer billing scales linearly with team size
Greptile

Greptile is an AI code reviewer built around a pre-indexed code graph, designed for cross-file reasoning during PR review on a single repository.
Key capabilities
- Pre-built repository code graph queried during each review
- Trace callsites and definitions across files inside PR comments
- GitHub and GitLab integration
- Custom prompts and review focus areas per repository
Pricing
- Cloud: $30 per seat per month, includes 50 reviews per seat, then $1 per additional review
- Enterprise: custom
- No published free Cloud tier
Pros
- Cross-file reasoning that diff-only reviewers can't match
- Predictable seat plus per-review pricing
- Good fit for product orgs on a single large repo
Cons
- Per-repo indexing model gets expensive across many repositories
- No free tier limits hands-on evaluation
- Narrower VCS coverage than CodeRabbit or Qodo (GitHub and GitLab only)
GitHub Copilot Code Review

Copilot Code Review is a GitHub-native AI review that drops into the existing PR workflow as an assignable reviewer.
Key capabilities
- Inline PR comments inside the standard GitHub review UI
- Assignable to a PR like a human reviewer
- Custom instructions per repository for review focus and style
- Runs on GitHub-hosted or self-hosted runners
Pricing
- Bundled within eligible GitHub Copilot plans (Business and Enterprise)
- From June 1, 2026, runs on GitHub-hosted runners consume GitHub Actions minutes; self-hosted runners do not
Pros
- Zero integration cost on GitHub; reviewers don't learn a new comment surface
- Familiar billing rails for teams already on Copilot
- Custom review instructions can match team conventions
Cons
- Review is grounded in the diff and limited repo context; thin on large codebases
- Actions-minutes consumption from June 2026 adds a new cost line for high-volume repos
- GitHub-only; teams on GitLab or Bitbucket are out
Sourcegraph (Code Search + MCP Server)
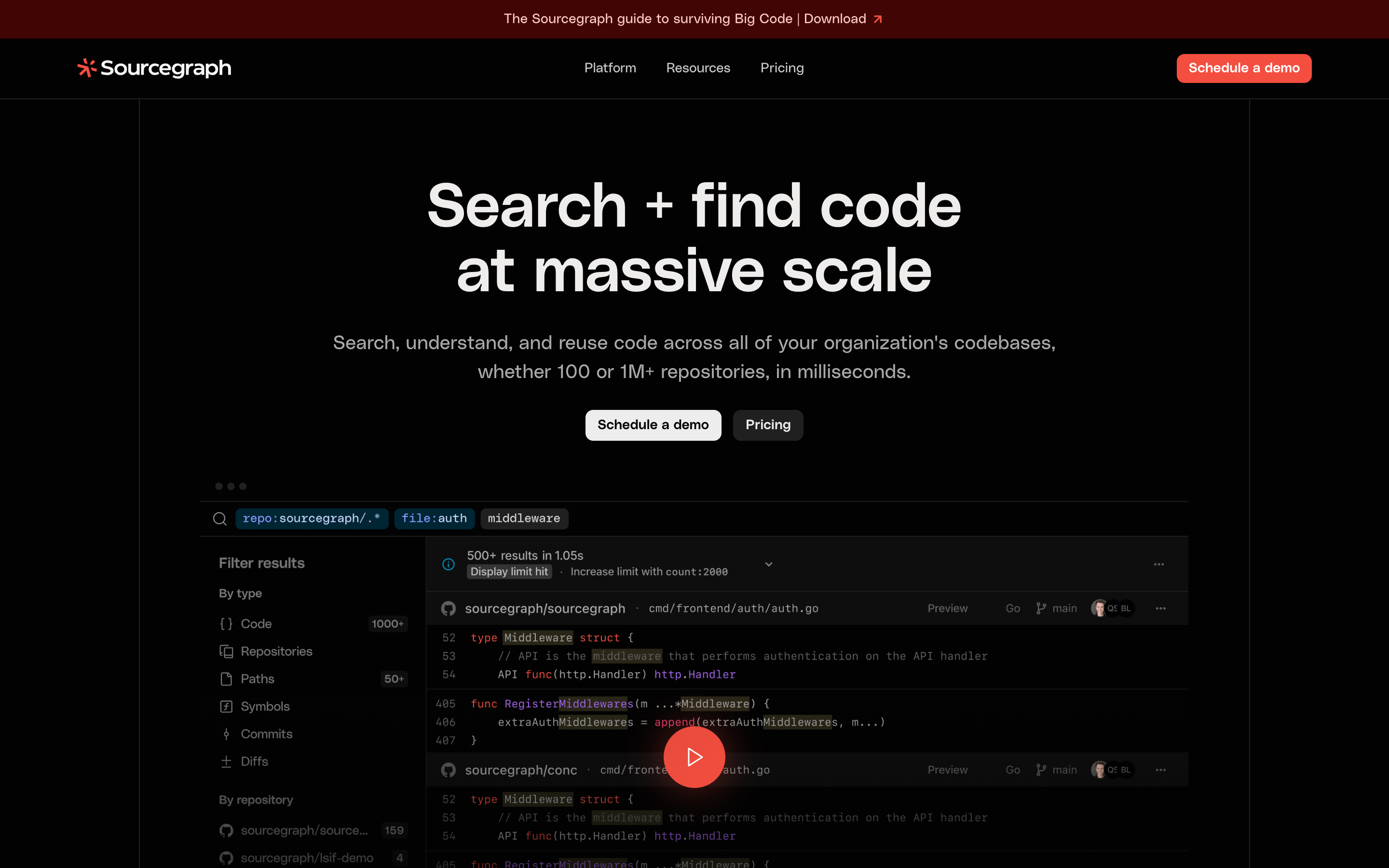
Sourcegraph is a context layer, not a PR bot. It pairs deterministic Code Search across multi-repo codebases with an MCP Server that any compliant AI agent can read from.
Key capabilities
- Exact-match and structural code search across every connected repository
- MCP Server that exposes the retrieval layer to Copilot, CodeRabbit, Qodo, or internal agents
- Code Insights and Code Monitoring for tracking patterns and regressions across teams
Pricing
- Sourcegraph Enterprise platform: starts at $16K per year, scales with team size; contact sales for a quote
Pros
- Repo-wide context that lifts the ceiling of any AI reviewer wired into it
- Single substrate for human reviewers, third-party PR bots, and Amp
- Pricing model lets small teams start on Amp's free or pass-through tier without a platform commitment
Cons
- Overkill for a single-repo team of five
- Platform pricing is "contact sales" outside the published $16K starting figure
- Not a drop-in PR bot; you still pair it with a reviewer who posts comments
Top Static Analysis & Rule-Based Code Review Tools
Static code analysis tools are a critical piece of the foundation everyone else builds on.
SonarQube Server / SonarQube Cloud

SonarQube (SonarCloud was renamed SonarQube Cloud in 2024) is the longstanding rule-based static analysis platform for code smells, vulnerabilities, and duplication. Sonar advertises 40+ languages and frameworks. Teams in regulated industries use it for hard quality-gate enforcement.
Key capabilities
- Quality-gate verdicts CI can block merges on
- Thousands of rules across 40+ programming languages and frameworks
- Pull request decoration on GitHub, GitLab, Bitbucket, and Azure DevOps
- SonarQube for IDE plugin for in-editor analysis before push
Pricing
- SonarQube Server Community Build: free, self-hosted, open-source rule set
- SonarQube Server Developer Edition: starts at $750 per year, scales with lines of code
- SonarQube Server Enterprise / Data Center: contact sales
- SonarQube Cloud free tier: $0 for public projects
- SonarQube Cloud paid: starts at $32 per month for up to 100K LOC, scales up to 1.9M LOC
Pros
- Deepest off-the-shelf rule library among the static tools listed here
- Both SaaS and self-hosted paths from one vendor
- Quality gates plug straight into existing CI
Cons
- Self-hosted Server takes real admin effort to keep tuned
- Default rules generate noise without per-team configuration
- Higher tiers are "contact sales" with no list price
Codacy

Codacy bundles SAST, SCA, secrets detection, and code quality in a single platform with one dashboard and per-seat pricing. It is the picked-because-it's-one-bill option in the static category.
Key capabilities
- SAST, SCA, secrets, and code quality scans in one console
- Pull request decoration on GitHub, GitLab, Bitbucket, and Azure DevOps
- IDE plugins for VS Code, Cursor, and Windsurf with MCP for Copilot or Claude
- Coverage reports and quality dashboards across repositories
Pricing
- Developer: free, $0 per developer per month, IDE-focused
- Team: starts at $18 per developer per month, up to 30 developers
- Business: custom pricing for organizations needing AppSec, DAST, and audit logs
- Open source: free
Pros
- One bill for SAST plus SCA plus secrets plus quality
- Free Developer tier covers solo IDE use without a credit card
- Wide VCS coverage out of the box
Cons
- Not the deepest tool in any single dimension
- Business-tier features (DAST, audit log, AI inventory) sit behind custom pricing
- Default rule sets need tuning before they stop generating duplicate findings
Semgrep

Semgrep is a pattern-matching SAST engine where rules are written in a syntax close to the target language. Security teams pick it for custom policies that off-the-shelf rule sets do not cover. The product family on the AppSec Platform is now Semgrep Code, Semgrep Supply Chain, and Semgrep Secrets.
Key capabilities
- Custom rule authoring in lightweight pattern syntax across 30+ languages
- OSS Semgrep CLI runs locally or in CI with no account required
- Cloud Platform adds managed rules, triage, and policy management
- Supply Chain (SCA) and Secrets scanning are sold as separate products on the same platform
Pricing
- Free: Semgrep Code at $0 per contributor per month, Semgrep Supply Chain at $0 per contributor per month
- Team: Semgrep Code or Supply Chain at $30 per contributor per month, Semgrep Secrets at $15 per contributor per month
- Enterprise: custom
Pros
- Write a custom rule in minutes for policies that no other SAST will catch
- OSS engine is genuinely usable without buying the platform
- Per-contributor pricing rather than per-seat scales with active engineers
Cons
- Out-of-the-box rule coverage is thinner than SonarQube's
- Pricing per product; a full Code + Supply Chain + Secrets stack adds up
- Custom rule authoring is a security-engineer skill not every team has
DeepSource

DeepSource is a polyglot static analysis platform that pairs analysis with Autofix. Instead of just flagging issues, it opens a pull request with the patch.
Key capabilities
- Static analysis across 20+ languages for quality, anti-patterns, performance, and security
- Autofix PRs that land as branches reviewers can merge directly
- Code formatting, OSS dependency scanning, and AI Review on the same platform
- Monorepo, audit log, API, and webhook support on the Team plan
Pricing
- Open Source: free
- Team: $24 per user per month billed yearly, includes $100 annual AI Review credit per user, then Standard $8 per 10K processed LOC or Advanced $15 per 10K processed LOC
- Enterprise: custom; required for self-hosted, BYOK AI Review, and SSO
Pros
- Autofix PRs convert findings into merged code instead of unread comments
- Single Team price covers static, formatting, and dependency scanning
- 14-day free trial includes $50 in AI Review credits
Cons
- Per-LOC AI Review billing on top of the seat price makes large repos expensive
- Self-hosting is Enterprise-only
- Rule coverage is narrower than SonarQube on legacy languages
Snyk Code

Snyk Code is the SAST piece of the Snyk AI Security Platform, sold alongside Snyk Open Source, Container, and IaC. The engine traces back to the DeepCode acquisition and uses ML-assisted analysis.
Key capabilities
- SAST scanning in CI and IDE for the major server-side languages
- Findings unified with Open Source, Container, and IaC results in one console
- Pull request checks on GitHub, GitLab, Bitbucket, and Azure DevOps
- Per-contributor licensing across the platform
Pricing
- Free: $0 per contributing developer, limited tests per product
- Team: starts at $25 per developer per month, minimum 5 developers, up to 10
- Ignite: $1,260 per year per contributing developer for organizations under 50 developers
- Enterprise: custom
Pros
- One platform if you also need SCA, container, or IaC scanning
- Free tier is real, not just a trial
- IDE integration catches issues before they hit CI
Cons
- Standalone SAST case is weaker than SonarQube unless you also need SCA
- Team plan caps out at 10 developers, forcing a jump to Ignite or Enterprise
- Per-contributor billing across multiple products stacks up quickly
Best Open-Source Automated Code Review Tools
Open-source tooling still does most of the work in most pipelines. Commercial tools above wrap or call these underneath.
PMD, ESLint, Pylint, RuboCop
The per-language linter staples behind nearly every CI pipeline. The commercial AI tools above frequently run several of these under the hood and summarize the output with an LLM.
Key capabilities
- ESLint: AST-based rules for JavaScript and TypeScript, pluggable rule packs
- Pylint: code style, error detection, and refactoring suggestions for Python
- RuboCop: style guide enforcement and autocorrect for Ruby
- PMD: bug pattern, copy-paste, and complexity checks for Java, Apex, and a handful of other JVM languages
Pricing
- All four are free and open-source
Pros
- Zero license cost and large community rule sets
- Run anywhere: pre-commit, CI, IDE
- Output integrates with Reviewdog and most commercial reviewers
Cons
- You own configuration, rule tuning, and noise control
- No semantic review across files
- Each tool covers one language, so polyglot stacks need four parallel pipelines
Reviewdog and Danger

Reviewdog and Danger are the glue layer between linters, custom rules, and the pull request. Reviewdog turns any linter's output into inline PR comments on changed lines. Danger runs scripted rules at the PR level for things like "every PR needs a changelog entry" or "files in /billing need a billing-team reviewer."
Key capabilities
- Reviewdog: reads checkstyle, RDJSON, and other formats from any linter and posts inline GitHub, GitLab, or Bitbucket comments
- Reviewdog: filters comments to changed lines only, cutting noise on incremental PRs
- Danger: rule scripts in Ruby, JS, Swift, Kotlin, or Python evaluated per PR
- Danger: comments, fails the build, or both, based on PR metadata and diff
Pricing
- Both are free and open-source
Pros
- Covers PR-level policy without paying for a commercial bot
- Composes cleanly with the OSS linters above
- Stays useful even after a team adopts CodeRabbit, Qodo, or similar
Cons
- You write and maintain the YAML, Dangerfile, and CI plumbing
- No AI reasoning; rules are exactly what you configure
- Debugging false positives means reading your own pipeline, not opening a vendor ticket
How to Choose the Right Tool for Your Team Size & Stack
Start from your team size, stack, and what you're trying to gate vs. inform. A solid code review tool plus a manual code review checklist outperforms a fancier tool used inconsistently.
For Startups & Small Teams
Five engineers, one or two repos:
- One AI code review tool on a free tier (CodeRabbit for OSS repos, bundled GitHub Copilot Code Review, or Amp's free tier).
- Open-source linters on CI (ESLint/Pylint/RuboCop) for deterministic checks on code style and code complexity.
- Optional: Snyk Code's free tier or Semgrep's open-source engine if you have security exposure.
You don't need a SAST platform, a quality dashboard, or an enterprise context layer. You need fast pull request feedback and a green CI signal.
For Mid-Market Teams
50 to 500 engineers, 5 to 50 repos:
- One AI reviewer chosen for your VCS (Copilot if GitHub, CodeRabbit, or Qodo if you need multi-VCS support).
- One code quality / SAST platform as a CI gate: SonarCloud, Codacy, or Snyk Code, depending on whether your driver is code quality, breadth, or security vulnerabilities.
- Reviewdog + Danger for custom rules per team.
The mistake we see most at this size is buying three overlapping AI reviewers because different teams adopted different ones. Pick one and standardize.
For Enterprise / Monorepo Environments
This is where many tool stacks start to fail. At enterprise scale, the AI reviewer's IQ ceiling is set by what context it can see. A reviewer who only reads the diff cannot tell you that the helper you just renamed is called from 47 places, two of which are public APIs documented in another repo. That gap drives platform teams to add Sourcegraph as a substrate underneath whichever AI reviewer they've standardized on.
The working pattern:
- A SAST platform as a required CI gate (SonarQube on-prem if needed, SonarCloud or Snyk Code otherwise).
- An AI reviewer wired to repo-wide context (Copilot, CodeRabbit, Qodo, or Amp, all of which can consume an MCP context layer).
- Code Insights or equivalent for tracking review patterns and code quality regressions across teams.
- Reviewdog/Danger for per-team policy rules nothing else handles.
Beyond Tool Choice, Giving Reviewers (Humans and Agents) the Context They Need
Here's the pattern we see at every Big Code customer. Two teams pick the same AI reviewer, but only one is happy with it. The other complains it produces shallow comments. The product is identical; the difference is what the reviewer can see.
A code review agent is a reasoning system on top of a retrieval system. When the retrieval layer is "the diff plus 100 lines around it," every AI reviewer regresses to the same ceiling.
Sourcegraph's role in code review isn't to be the 14th PR bot. It's to be the substrate everything else reads from:
- Code Search gives a reviewer (human or agent) deterministic, exact-match results across every repo. When an agent reasons about whether a function change is safe, it can issue the queries a senior engineer would: "Where is this called?", "What tests exercise this path?"
- MCP Server exposes that retrieval layer over the Model Context Protocol so any compliant reviewer or coding agent can consume it. Platform teams plug Copilot, CodeRabbit, Qodo, and internal reviewers into the same MCP server and get higher-quality feedback because retrieval has gotten better.
- Code Insights tracks patterns AI reviewers should be enforcing across the codebase: deprecated API usage, migration progress, and security patterns.
- Code Monitoring alerts agents and reviewers when specified patterns enter the codebase, which is the difference between catching a bad pattern in review and catching it three days after merge.
This is also why the role of human reviewers shifts in agent-driven workflows rather than disappearing. With repo-wide context, the AI handles the mechanical, cross-cutting parts of code review. Humans focus on judgment calls and architectural decisions. That requires the context layer to actually exist.
Conclusion
The honest takeaway after comparing these 13 review tools: the choice between rule-based and AI-powered isn't a choice. Most engineering teams need both to keep code quality high, plus a context layer if they're operating at meaningful scale. The interesting variable in 2026 isn't which AI reviewer wins on a benchmark. It's how much repo-wide context the reviewer can actually see when it runs across pull requests.
If you're picking a stack today, start with the team-size pattern that matches yours, add the AI reviewer that fits your VCS, and gate CI on a SAST platform you trust. If you're at Big Code scale, the next decision is the substrate underneath all of it. See how Sourcegraph powers code review at Big Code scale, or talk to our team today to understand how Sourcegraph can improve code quality and your review workflows.
Frequently Asked Questions
What are the best automated code review tools?
The best fit depends on your stack and team size. For most mid-market teams, the working pattern is one AI reviewer (CodeRabbit, Qodo, Copilot Code Review, or Amp) plus one rule-based platform (SonarQube, Codacy, or Snyk Code) plus open-source linters in CI. For enterprise monorepos, add a context layer like Sourcegraph so any reviewer can read repo-wide context.
Are automated code reviews effective?
Yes, when used correctly. Rule-based static analysis catches a deterministic class of bugs, security vulnerabilities, and policy violations cheaply on every pull request. AI code review catches a more semantic class of issues and is genuinely useful when grounded in a real repo context, helping teams improve code quality at scale. The failure mode is letting comment volume train reviewers to ignore the bot. Effective teams tune severity thresholds, gate CI on a small set of high-confidence rules, and let the noisier feedback be advisory.
Can AI replace human code review?
No. AI reviewers are good at catching mechanical bugs and applying patterns consistently across hundreds of pull requests. Humans are still better at architectural decisions, judgment calls about scope and risk, and mentoring. The right code review process in 2026 puts AI in the first-pass reviewer role and humans in the deciding role: focused on architecture, risk, maintainability, and judgment.

